
実際の業務やKaggleといったコンペをやってみると、100個以上の特徴量を扱わないといけないなんてことが出てきます。
そんなとき私の場合はデータのカラムだけ取り出して一度エクセル等にまとめて整理することが多いんですが、みなさんはいかがでしょうか。
表形式にすることで多少は整理されて分析を進めやすくなるのですが、
”どのように整理するか?”
という点を意識して今回はデータの整理方法のオススメを2つ紹介したいと思います。
整理をする目的
データを整理するのに特に理由なんてものはないのですが、
強いて挙げるとすると、データ取得の手戻りが軽減されます。
機械学習プロジェクトは精度改善を繰り返すサイクルを回していきます。
その時にデータがキチンも整理されていることで、次に入手するデータの優先順位を意識したり、
または不要なデータを削除したりといったことに活用が可能となるです。
次に紹介する2つのやり方は私が業務でも取り入れているやり方ですので是非参考にしてみてください。
①:目的変数との関連性に着目する
データ分析や機械学習の予測モデルを作成する際には、必ず目的変数と呼ばれる分析の中心になる特徴量が存在します。
その特徴量と関係性が強い順に並べていくことで、データの重要度(人間が考える)を意識しながら整理することが可能です。
イメージとしては以下の図ではとあるパスタ屋の評価を目的変数とした場合の整理例を示します。
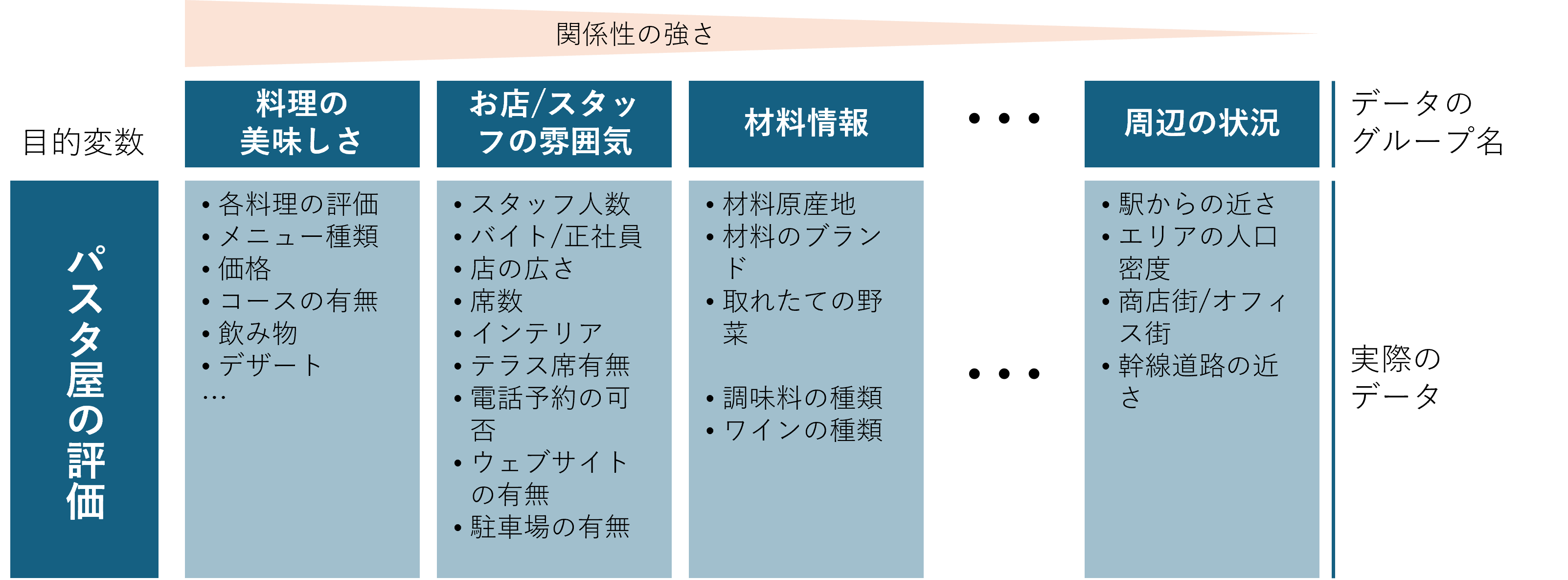
図:関連性ごとにデータを整理する
上のイメージのように、一番左に目的変数を置いて、関連性の強いと思われるデータを順に並べていきます。
このとき、データをグルーピングすることが重要で、どのようにデータを分けるかは最初に考えておく必要があります。
目的変数との関連の強さを考えたり、データをグルーピングしたりするにはかなり深くデータを理解してる必要があります。
このように整理することで、特徴量選択として関連の強い順にデータを使っていくといった使い方も可能です。
②:データの時系列に着目する
続いてはデータの発生(したと思われる)順番に整理していくやり方です。
図のイメージはクレームの要因分析ですが、整理については料理の順番になぞらえて説明するとわかりやすいかもしれません。
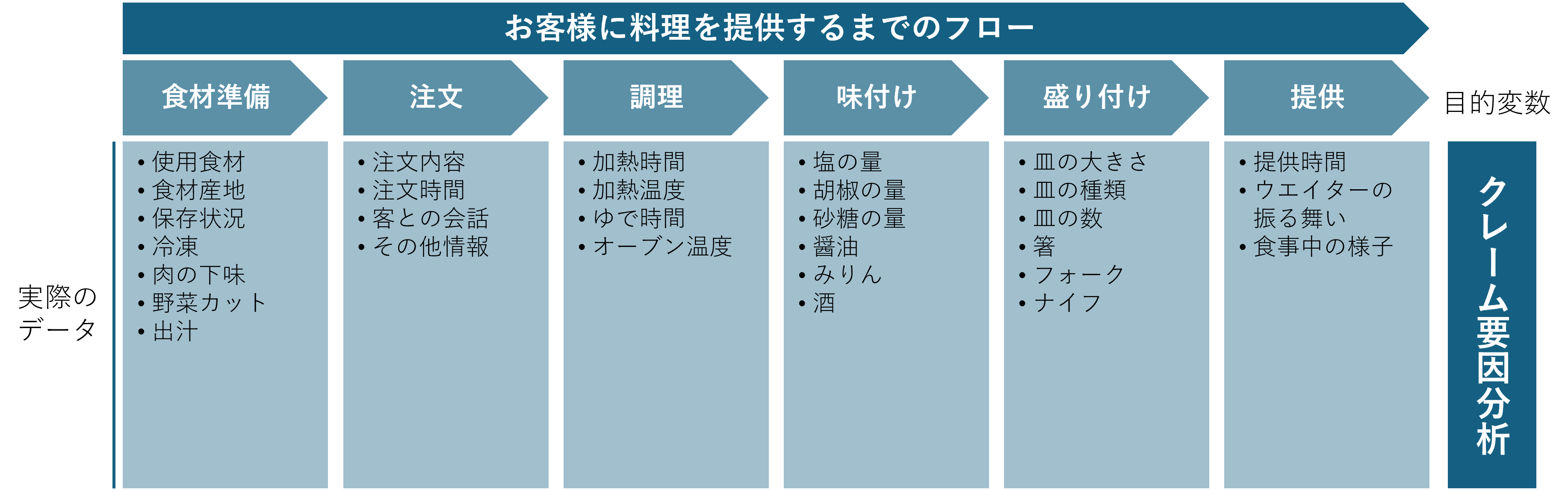
図:データ発生を時系列順に整理する
データを純粋に工程順に並べるので理解しやすく、整理自体容易にできるので便利です。
まとめ
データの整理方法について以下の二つを紹介しました。
①:目的変数との関連性に着目する
②:データの時系列に着目する
実際私が整理するときはもう少し複雑に整理します。
例えば、縦方向のデータについても食材や条件ごとに並べ方を工夫したりします。
このように無秩序に並べられているデータを少し並び変えるだけでも、見やすさや理解のしやすさは段違いに変わってきます。
何気ないことですが、ぜひ皆さんも取り入れてみて少しでも効率が上がれば幸いです!


コメント