
今回は過去に実施されたSignateのシェアサイクルの利用予測に挑戦しました。
実際に投稿してみた結果、ランキング100位(暫定評価3.67)を切れました!
今回はそのノウハウを共有したいと思います。
※コードの公開はしません。方針だけ
データ概要
用意されているデータは以下の5つ
- 自転車の台数状況データ(status.csv)
- 利用者の移動履歴データ(trip.csv)
- ステーション情報(station.csv)
- 気象情報(weather.csv)
- 投稿用サンプルファイル(sample_submit.csv)
※データ詳細はこちら
複数のデータが用意されており、すべての情報を使おうとするとかなり複雑なデータ結合が必要となる。
特に、「利用者の移動履歴データ」をどう利用するかが精度向上のカギとなる?
とみていたが、実はあまり使えなかった…
モデル作成の方向性
時系列データをどう扱うか?
今回のデータは時系列データを用いた予測となり、ARIMAやProphetといった時系列特有のトレンドを意識したアルゴリズムを用いることが一般的だが、今回は時間は意識しつつ通常の回帰問題としてモデリングを行った。
また、重要なのが公式のコンペの説明でも触れられているが、時間の前後関係を意識しないとリーケージが発生する可能性がある。
リーケージとは、予測時点では知り得ない未来データを意図せず使っており、評価上の精度が異常に良くなる現象である。
対策としては、データの一部を検証用として適切に切り離しておくホールドアウト法による検証を行うことで検知することができる。(交差検定では精度が良いが、ホールドアウトでは極端に精度が下がる)
複数ある予測対象日をどう扱うか?
概要ページや自転車の台数状況データ(status.csv)の予測対象となるデータに注目すると、”2014-09-01”以降、ある特定の日の1時~23時を予測対象とするようにと指示がある。
つまり、やろうと思えば、予測対象の時間帯の直前までのデータを使ってモデリングを行うことができるが、これをやろうとすると最大で予測対象日分(120個)のモデルを作成することになる。
しかしながら、初期の段階では120個ものモデルを作成するのは時間も手間かかってしまい、あまり現実的ではない。(精度改善の段階まで進んだのであればトライするのはあり)
そこで、まずは予測対象日のない”2014-08-31”までのデータを使ってモデリングを行い、”2014-09-01”以降の予測対象日となっているタイミングの予測を一気に行う。
これにより、作成するモデルは1つで済み、予測回数も1回で済む。
しかも、予測対象日以降のデータは学習に使わないのでリーケージの心配もグッと下がる。
おまけに、これだけでも結構よい精度が出てしまう。

実は、今回時系列モデリングを選択しなかったポイントがここにもある。
時系列モデリングでは性質上、予測対象日から近い時間のデータを参考にすることで精度よく予測を行う。
つまり時系列モデリングを選択してしまうと、予測対象直前のデータを使用するために120個のモデルをどうしても生成する必要が生じてしまう。(そうしないと精度が酷いことに)
一方、通常の回帰問題であれば、データセット内の前後のデータで強い関連性があるわけではなく、予測対象の説明変数によって予測値が出力される。
つまり、何も予測対象の直前のデータを使わなくてもOKということになるので、モデル作成負荷を下げることができる。
(精度改善の段階なのであれば、もちろん使えるデータ数を増やすという意味でもモデルを複数作成し、それぞれ予測対象直前のデータを用いることも考えられる)
特徴量エンジニアリングをどうするか?
結局試した特徴量エンジニアリングは次の通り。
- City2だけモデルを分割
- 曜日情報付与
- ステーションの属性情報を付与
- 天気情報付与
- ゼロ時台のデータを削除
City2だけ分割した理由は、各Cityに分けてターゲットの時間推移をみると、明らかに縦軸が大きく、利用者の規模が異なるため。
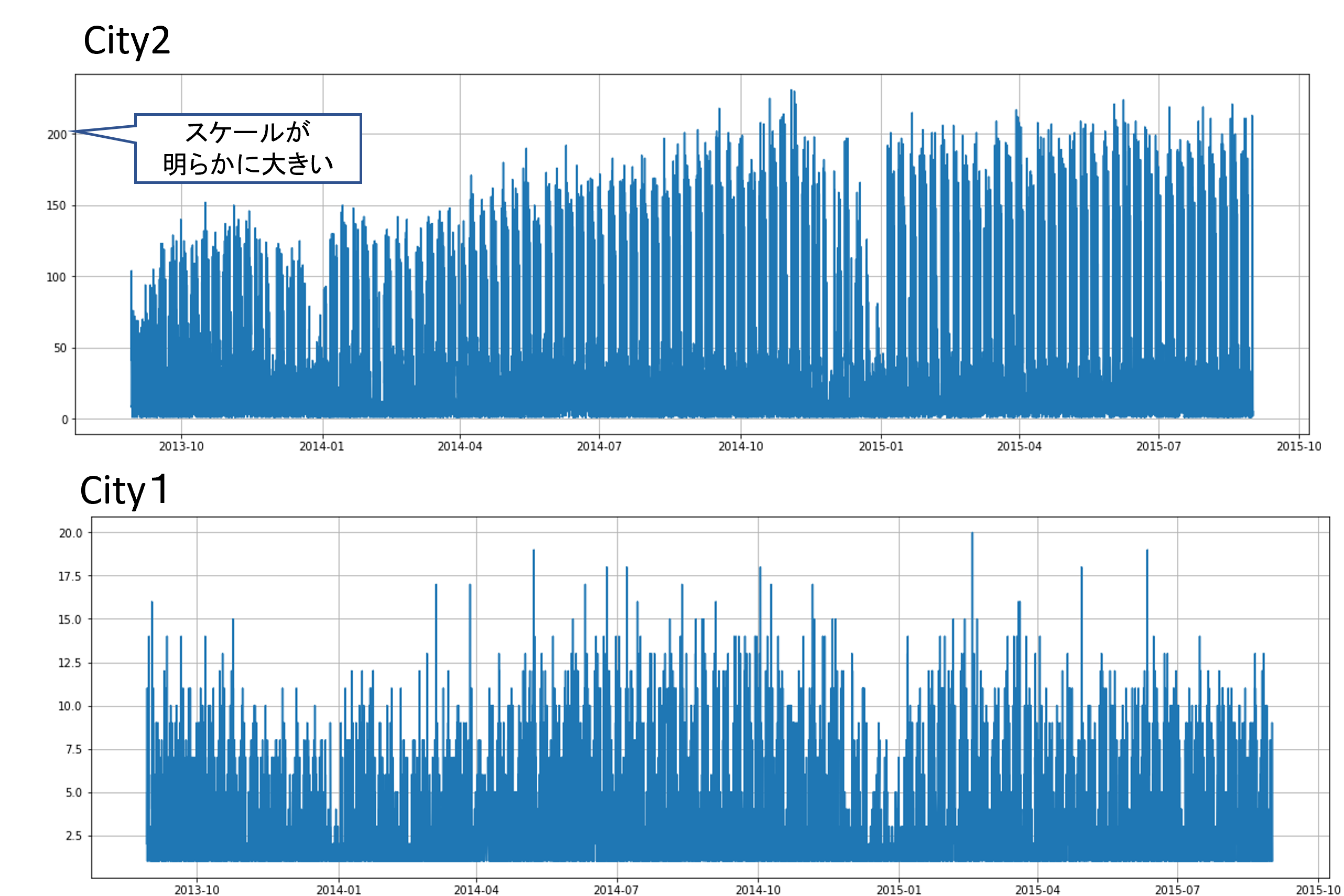
それ以外の特徴量の加工は与えられたデータセットを結合したくらい。
気温や降水確率、湿度といった天気予報は自転車に乗るかどうかにとても効いて来ると考えていたが、直前の天気情報でないと逆に精度が下がってしまった。
やろうと思ったけど面倒くさくて断念した特徴量エンジニアリング案
- 過去同曜日、過去同時間の情報(平均等)を付与
曜日や時間帯によって自転車の使われ方にパターンがあるような気がしたから。だが、データ集計が面倒 - 天気情報に関する変換
天気情報はただの数値であるため、自転車に乗ってどこかに行きたいという人間の気分に合わせたい。そこで人間が快適と判断する温度や湿度、風の強さからどれくらいかけ離れているか(不快に感じるか)を特徴量として入れたかったが、もちろん面倒なのでやめた - 緯度経度の情報から地域の特色を特徴量に入れ込む
データにあるCityは正式な地名が伏せられているのに、なぜか緯度経度は数値として与えてくれている。この緯度経度を検索すると米国のサンフランシスコ周辺の地域であることがわかる。つまり観光地を含む地域なのでエリアや周辺の建物によってはイベントが行われたりするんじゃないかと思うが、当然イベントデータなんて準備できないので断念 - 夜中~朝方の時間帯は0時時点の自転車台数をそのまま予測値とする
夜中に自転車を使ってどこかに行く人は恐らく少ない。予測対象(1時)直前の自転車台数が恐らく朝の6時くらいまでは同じだろうと踏んだ、が…
ところが、本コンペの表彰者のコメントを見ると…
A. 工夫した特徴量はシンプルで、年、月、日、曜日などを日付データを主に数値化して活用しています。また0時時点の台数は精度への影響が見られなかったため、特徴量からは外しています。
(https://signate.jp/articles/competition-report-sc2021fall-20211215)
これはいったいどういうことだろうか?普通に考えたら、夜中に自転車を使う人は限りなく少なく、予測対象直前の0時の自転車台数がそのまま1時、2時…朝方まで続くと考えられるが、実際はそうではない、ということ。
この理由はいったい何なんでしょう?運営会社が各ステーションの自転車台数の偏りを均すために故意的に移動させているんでしょうか?
データを見れば12時~1時の間で不自然に台数が変化しているはず。(しかし面倒なのでデータは見ない。)
結論
冒頭に述べた通り、暫定評価3.67を取ってから手は止まってしまった。
最終的な処理は以下の通り。
- 天気情報といった与えられたデータを結合した
- 曜日を追加した
- 「City2」だけモデルを分けた
- 直前のデータを使うためにモデルを120回作成した(モデル完了まで1日かかった)
上記だけでそれなりの精度が出てしまったというのと、表彰者も特に複雑な特徴量エンジニアリングを行ったわけではなく、逆に何もしないのことで素材の味が活きている的な雰囲気を感じ取ってしまった。
という理由でやる気が…


コメント