
本記事では前回作成したデータセットを使ってモデリング、評価をやっていきます!
競馬予測チャレンジ目次!
- データ取得編1(過去のレースデータ取得)
- データ取得編2(スピード指数取得)
- 特徴量エンジニアリング編
- モデリング、評価編 ⇦本記事はココ
- 実践編
方針
ターゲットは?
機械学習モデルの性能を高めるために評価が必要となります。 評価を行うために、まずは何を予測ターゲットにするかを明確にしましょう。 今回は各レースで優勝する馬を予測、つまり単勝を的中させたいので少し幅を持たせて3位以内に入る馬を狙っていきます。ターゲットは各レースで3位以内に入るかどうかの2値分類問題として評価していきます。 したがって、馬券の買い方は1レースごとに3位以内に入るであろう3頭分の馬券を購入(300円)することになります。
モデリング
ターゲットが決まったところで、次は機械学習アルゴリズムですが今回使うのはみんな大好きLightGBM Classifierを使っていきます。 ちなみにパラメータチューニングなんて野暮なことは行いません。男なら己の肉体のみで勝負する!といった感じです。
評価の仕方は?
通常機械学習の評価は、2値分類の問題であればAUCやLogLossと呼ばれる評価指標数値を使って評価を行います。
しかし、今回はもっと実用的な観点で評価を行うために実際に馬券を買った場合にリターンがいくらになるか?を示す回収率で評価をしていきます。
回収率を以下のように定義します。
回収率 = 儲けの合計 ÷ 掛け金の合計 × 100
= (オッズ × 掛け金)の合計 ÷ 掛け金の合計 × 100
この時、掛け金は馬券を1枚買う想定なので100円で固定となります。
この回収率が100%を超えるようであれば、儲けあり!
逆に回収率100%を切ってしまうと……楽しんだ金額はプライスレスということですね。
予測方法おさらい
回収率が決まったら流れを一度整理したいと思います。
- 2015年から2019年までのデータを使ってモデル作成
- 2020年の1年間の東京のデータを使って予測
- 予測結果から回収率を算出
実際にモデリング
まずはデータの分割です。2015年~2019年を学習データ、2020年を評価用データとして分割していきます。
#2019年までのデータを学習用とする
df_tr=df__[df__['date'] <= '2019-12-31']
#2020年以降かつ東京のデータをテスト用とする
df_ts=df__[(df__['date'] >= '2020-01-01') & (df__['race_place'] == 5)]
#不要なデータを削除
X_train=df_tr.drop(['date','target'],axis=1)
y_train=df_tr['target']
X_test=df_ts.drop(['date','target'],axis=1)
y_test=df_ts['target']
続いて、学習させていきます。
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_auc_score
from lightgbm import LGBMClassifier
#回収率計算の関数
def return_rate(result):
th=[0.50,0.60,0.70,0.80,0.90]
idx=['Pay','Return','回収率','正答率','レース数']
temp_=pd.DataFrame(index=idx)
for t in th:
temp=result.query('target確率 > @t').copy()
temp['単勝']=temp['単勝'].map(lambda x:1 if x == '---' else float(x))
kakekinn=temp.shape[0]*100
mouke=((temp.query('着順 == "1"')['単勝'] * 100).sum())
seito=temp.shape[0]/result.query('着順 == "1"').shape[0]*100
if temp.shape[0] == 0:
return_rate=0
else:
return_rate=mouke/kakekinn*100
temp_['th='+str(t)]=[int(kakekinn),int(mouke),return_rate,seito,temp.shape[0]]
return temp_
#学習
lgbm = LGBMClassifier()
lgbm.fit(X_train,y_train,eval_metric='AUC')
#AUC
auc=roc_auc_score(lgbm.predict(X_test),y_test)
#混合行列
cm=confusion_matrix(lgbm.predict(X_test),y_test)
#結果表示
print('----混合行列----')
print(cm)
tn, fp, fn, tp = cm.flatten()
print('AUC:',auc)
print('的中率:',tp/y_test.shape[0])
#回収率を求めていきます
result=df[df['日付'] >= '2020-01-01'][['着順','target','単勝']].copy()
result=pd.concat([result.reset_index(drop=True),pd.DataFrame(lgbm.predict_proba(X_test))[1]],axis=1)
result.columns=['着順','target','単勝','target確率']
return_rate(result).astype(int)
実際に回してみると…
| th=0.5 | th=0.6 | th=0.7 | th=0.8 | th=0.9 | |
| Pay | 11,000 | 6,200 | 2,500 | 600 | 0 |
| Return | 11,320 | 5,950 | 4,710 | 0 | 0 |
| 回収率 | 102 | 95 | 188 | 0 | 0 |
| レース数 | 110 | 62 | 25 | 6 | 0 |
なんということでしょう。。。いとも簡単に回収率100%を超えてしまいました。
さて、明日辞表出して会社辞めてJ〇Aに行くか…
表のthは2値分類のしきい値を表しています。LightGBMの出力は予測確率なのでしきい値をいくつにするかによって、予測結果の0と1を調整することができます。
例えばth=0.9というのは、機械学習モデル君が90%以上の自信を持って当たると予測して初めて予測結果1、それ以下をゼロと出力することを意味します。
モデルの評価
今回作成したモデルの妥当性を見るために、Feature Importanceを見ていきます。
これは、ターゲットを予測する上でどのカラムの影響が強かったのかを示してくれます。
pd.DataFrame(lgbm.feature_importances_, index=X_train.columns, columns=['importance']).sort_values(by='importance').plot(kind='barh',figsize=(9, 8))たった1行です。その結果は、、、
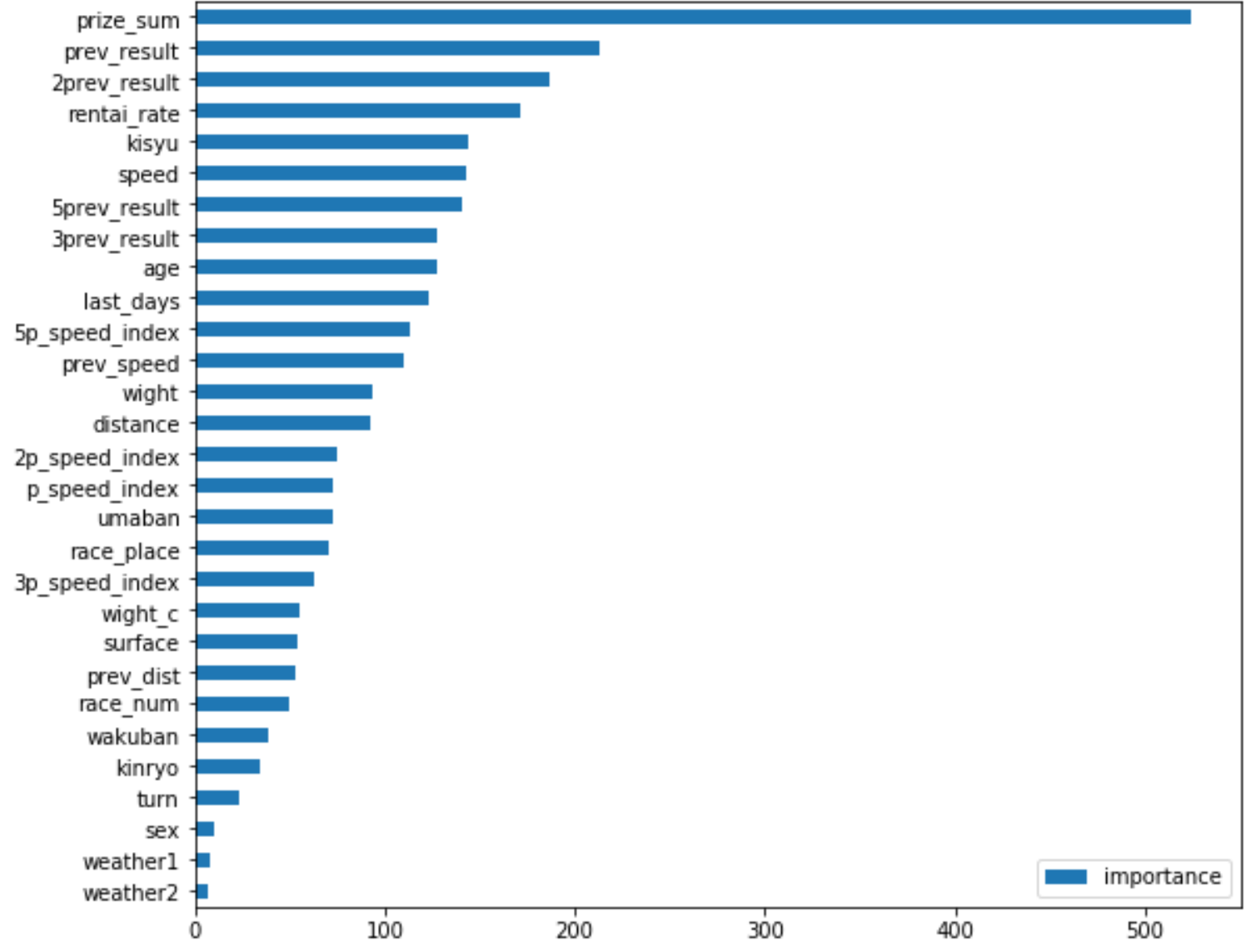
最も効いていたのが、prize_sum(獲得総賞金額)ということで過去の実績がある馬が最も影響を与えるということがわかりました。
続いて、prev_result(前回レースの着順)やrentai_rate(連帯率)についても同様に過去の実績と捉えることができます。
…あれ?頑張って取得したスピード指数はあんまりなのですか…?
さらに精度を上げる案
あくまで案です。実施はしてません。
難易度:簡単
- データ数を増やしてみる
- 東京競馬場のみのデータでモデリングしてみる
- LightGBMのチューニングをしてみる
難易度:普通
- 馬の血統情報をスクレイピングで取得し、入れてみる
- その他の競馬で使われる指数を入れてみる
難易度:Max
- 上記を取り入れ、Deep Learningを使って学習してみる
これら以外にもいろいろと精度を上げるやり方はあるかもしれません。
そして、やるとどこまで精度が上がるんでしょうか。気になりますね。
まとめ
- スクレイピングでデータを取得し、LightGBMを使ってモデリング実施
- あれよあれよという間に回収率100%を突破
- 本当に実践いていいのか悩む ← New!
- もし、的中するのであれば第二の人生を考える ←New!
みなさんも邪なことは考えずに楽しんでデータサイエンスをやりましょう。
次回、実践編!
ですが、いつになるんでしょうか…


コメント