
データサインティスト初心者のぬる~い業務内容を振り返ります。
最近、とある案件にアサインされたため本格的にデータサインエスの日々が始まりました。
今日はお客様とデータサイエンスプロジェクトを始めるにあたってお客様からいただいたデータを確認するための基礎集計について触れていきたいと思います。
基礎集計その1 エクセルを使ってデータを生で見る
お客様からデータをもらったらまず最初にやることは、データを生で見るということです。
あっしの場合、~50MBくらいのデータ容量であればエクセルを使ってしまいます。
もちろん、データ容量が100MBを超えるようであればPythonさんを使います。
エクセルでデータを見るときはそこまで本腰を入れて確認するわけではありません。
なんとなーく、直感に頼ってデータを眺めます。
確認したいところは次の点
- カラムにどんな項目が入っているのかざっと見る
- なんとなくのカラム数
- 手入力されたと思われる文字列や数値の項目
- 加工が必要そうな項目
- パッと見でNaN(欠損)が多そうか見る
- 目的変数になりそうな項目
本当になんとなーくで見ています。ただ、できることならデータをもらった瞬間に見ておきたいです。
なぜなら、経験を積んでいくと意外とパッと見ただけで加工の負荷やモデリングの良し悪しが想像できて、もしお客様と打ち合わせ中にその場で情報を引き出せる可能性があるからです。
欠損が多いところがありますねー
データが入ってない所は担当者が面倒くさがって入力しないんですよ~
みたいな会話がお客様とできるだけでOKです。
相手のデータに対する理解度がわかったり、担当者しかわからない情報が引き出せたりできれば儲けもんです。
あくまでパッと見ですので過度な期待や憶測はNGです!
基礎集計その2 Pythonを使ってデータをしっかり見る
ここからはなーんとなくではなく、しっかりとデータを見ていきます。
全データ数の確認
まず最初に確認するのは、データ全体のカラム数とレコード数。
import pandas as pd
df = pd.read_csv(r'C:\Users\...\~.csv', encoding = 'shift_jis')
df.shape
実行結果
(1000,30)実行結果の数字は(レコード数、カラム数)を意味しています。
まずはデータ全体の件数を確認しましょう。
データの形式、欠損数、ユニーク数、最大、最小、平均を求める
次は基礎統計量を求めていきます。表としてまとめて表示するようにしましょう。
自分の場合は次のコードを使いまわしています。見たいデータに合わせて適宜修正は必要になりますが、基本的にはこれで基礎統計量はある程度は求まってしまいます。
import pandas as pd
df=pd.to_csv(r'C:\Users\...\~.csv', encoding = 'shift_jis')
# 基礎統計量として、データ型、カウント数、ユニーク数、欠損数のほかに、偏り率やゼロ率、欠損率も求めています。
kiso=pd.DataFrame()
ind=pd.DataFrame(df.dtypes,columns=['data型']).index
kiso=pd.concat([pd.DataFrame(df.dtypes,columns=['data型']),
pd.DataFrame(df.count(),columns=['カウント数']),
pd.DataFrame(df.nunique(),columns=['unique']),
df.describe().T,
pd.DataFrame(df.isnull().sum(),columns=['欠損数'])
],axis=1,sort=False)
kiso['偏り']=kiso['freq']/kiso['カウント数']
kiso['ゼロ率']=df[df==0].count()/df.shape[0]
kiso['欠損率']=kiso['欠損数'] / df.shape[0]
kiso=kiso.drop('count',axis=1)
data_o=['data型','欠損率','網羅率', '偏り','ゼロ率', 'カウント数', 'unique', 'mean', 'std', 'min', '25%','50%', '75%', 'max', '欠損数']
kiso=kiso.loc[:,data_o]
# 以下データフレームをcsvに保存
kiso.to_csv(r'C:\Users\...\集計結果.csv',encoding='utf_8_sig')自分で言うのもなんですが、結構優秀です。
後はcsvにした集計結果をエクセルで見やすく加工してやればOK!
皆さんもぜひボタン一つで計算されるような定形コードを作ってみてください。
データの可視化
さて、次はデータの可視化です。このステップは非常に重要です。
この作業の目的は次になります。
- データの偏りを視覚的に確認する
- 外れ値、異常値を見つけ出す
- データとデータの関係性(相関がありそう?)を確認する
これらを確認する方法としては、Pythonのmatplotlibを使って可視化してもいいし、エクセルでグラフ化してもOKです。扱うデータ数に応じて使い分けてください。
データの偏りを視覚的に確認する
データの偏りについては、まずはヒストグラムを見るのが良いでしょう。偏りと同時にデータの性質を確認することができます。
ヒストグラムを確認して山が複数見られる場合、異なる性質のデータが含まれる可能性があります。
これを見逃してはいけません。なぜならば、モデル作成を行う段階で精度をより高めるために「データをどう分けてモデリングするか」という話になる可能性があるからです。
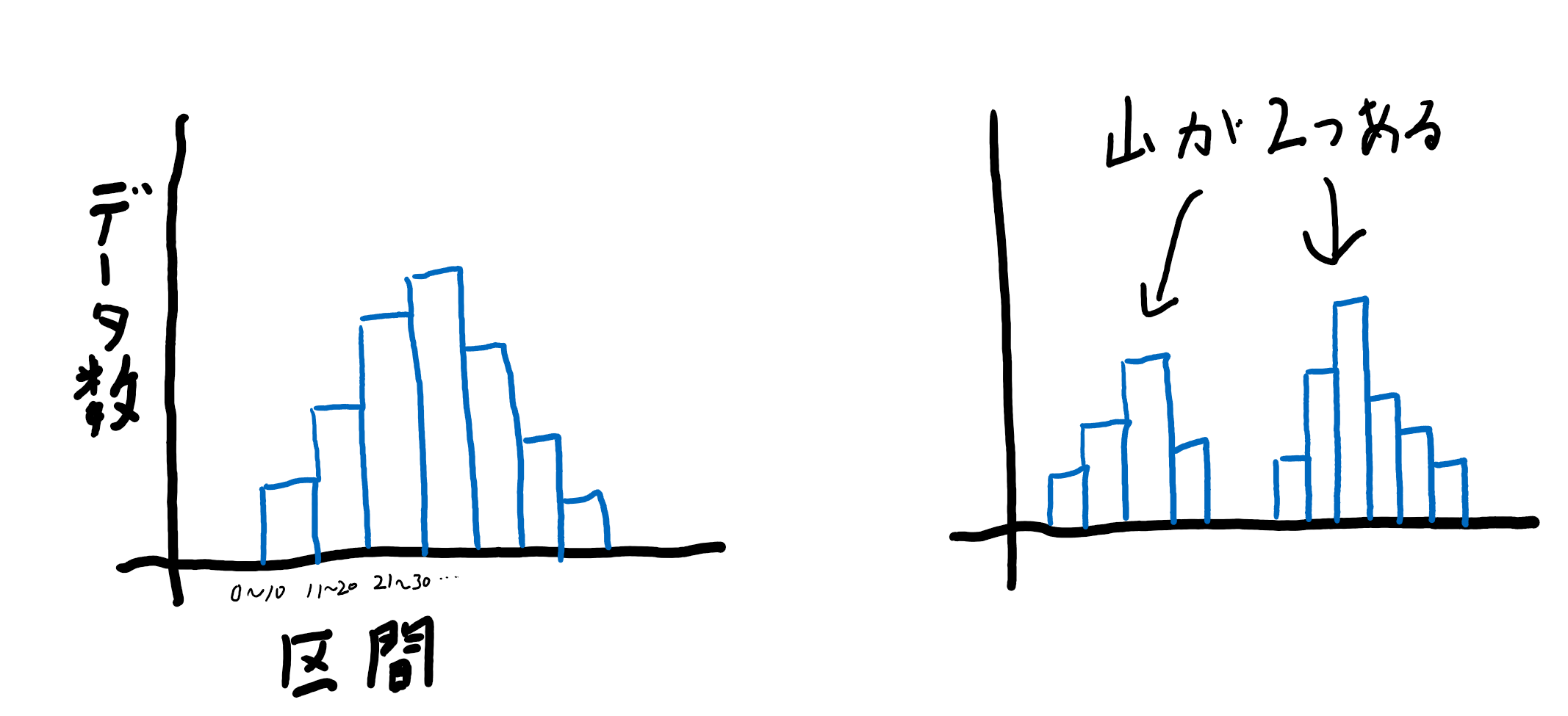
ヒストグラムを見て複数の山がみられるとき、それはデータを分割するヒントになるのです。
外れ値、異常値を見つけ出す
外れ値、異常値についてはヒストグラムでは見つけづらいので、データを見て最大最小値を確認するか、散布図を使うのが良い場合があります。
外れ値や異常値は定義が難しく、本来本当に外れ値や異常値なのかどうかの判断を行うための議論が必要です。
どちらにしろ、外れ値や異常値はモデル作成時に悪影響を与えかねないので何も考えずに外してみるのは一つの手ですが、テーマに振り返ったときに正しいのかどうかは考えましょう。
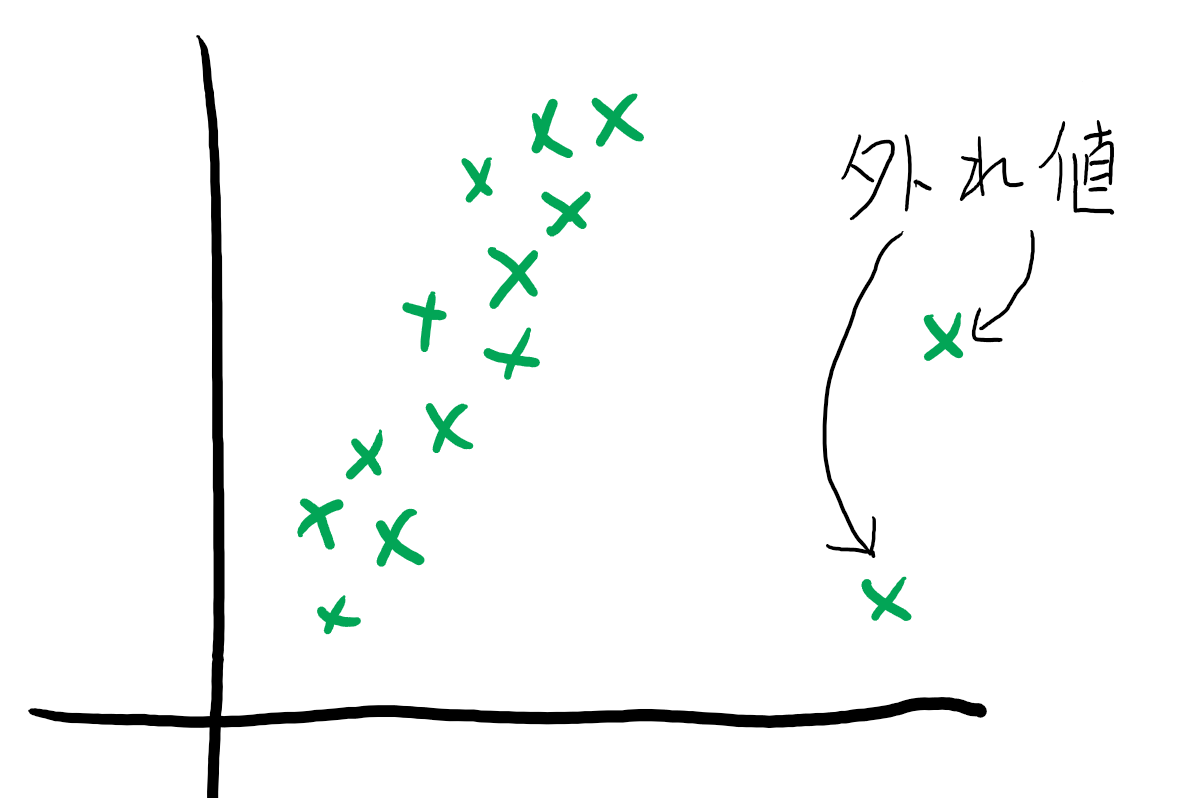
データとデータの関係性を見つける
最後に、データ同士の関係性に着目しましょう。
Pythonを使うと相関係数の計算が簡単にでき、またヒートマップにもしてくれるので一目でデータ同士の相関を確認することができます。
エクセルでもアドインにある分析を追加すればデータを指定するだけで簡単に相関係数を求めることができます。
相関係数を見るときは特にターゲットとの相関を見ることが多いです。
実際にデータの内容に詳しい担当者であれば、どの項目がターゲットに影響を強く与えるのかを経験的に見つけることができる場合もありますが、相関係数を求めてみると意外な組み合わせによって関連性が見られることもあります。
分析の観点から、相関が強いということは多重共線性が疑われる場合があります。
多重共線性とは似たような挙動を示す複数のデータで、モデルの予測精度に悪影響を与える可能性があります。
例えば部屋の広さを表すデータが「㎡」と「畳」両方データ内にあった場合、これはほとんど同じ挙動を示すために多重共線性となります。
しかしながら相関が高いからと言って必ずしも多重共線性が発生し、モデルの予測精度に悪影響があるわけではありません。
可視化をする際に、その先のステップであるモデルの精度向上の可能性の一つとして頭の片隅に残しておきましょう。
以上、データの基礎分析でした。
基礎分析は奥が深く、実際にいただいたデータに合わせて確認しないといけない内容が変わってきます。
例えば、様々な拠点からデータをかき集めて一つのファイルとした場合、データの傾向が各拠点ごとに一致しているかなど、事前に統計的に検定を行い、確認する必要があります。
私もまだまだ勉強中なので、実際に体験次第共有したいと思います!
以上!


コメント