
前回の記事ではChatGPTを使うことでエクセルやPDFファイル、そして画像といった非構造化データからデータを抽出し、構造化データが作れることを検証しました。
今回は、ChatGPTを使って構造化データに対して加工や分析をやっていきたいと思います。
結論から述べると、もはやデータ分析は生成AIにやらせる時代がくるでしょうね。と言わざるを得ない結果に。
データ概要理解
与えられたデータがなんのデータなのかを推測させる
まずはKaggleの有名なデータ、タイタニックの生存予測のデータをノーヒントで投げてみます。
質問内容:「このデータは何でしょうか?」
回答:

さすがにタイタニックのデータでは有名すぎたようですね。
普通にデータをアップしただけで何のデータセットか当ててきました。
続いてはこちらのデータはどうでしょうか。
質問内容:「このデータは何でしょうか?」
回答内容:

見事に正解です。
投げたデータは厚生労働省が出している2024年新型コロナウイルス感染者数の推移です。
一つ、疑問が残ります。どうして新型コロナウイルスの新規感染者数のデータだとわかったのでしょうか?聞いてみます。
質問内容:「どうして新型コロナウイルスの新規感染者数だとわかったんですか?」
回答:

すごいです。
データのカラム名や日付、そして数値の傾向から判断してなんのデータか推測しているようです。
データを可視化をさせてみる
データ分析の基本、可視化をやってみたいと思います。
質問内容:「上記データの時系列グラフを生成してください。表示させる都道府県は関東のみにしてください。」
回答:
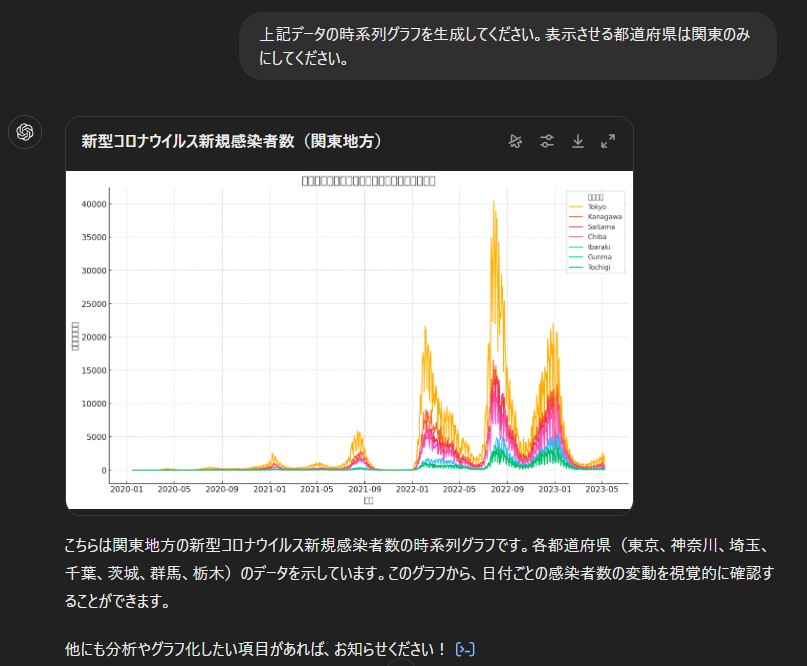
なぜかグラフのタイトルや軸は文字化けしています。
確認のためエクセルでグラフを自作しましたが中身は見事に合っています。
さりげなく、関東と限定してひねりを加えたのですがこれくらいは問題なく理解してくれるようです。
このグラフは生成したものなのか引用したものなのかはわかりません。
グラフから示唆を出す
質問内容:「上記、関東に絞ったグラフをもとに、グラフから言えることを提示してください。」
回答:

「東京は人口が多く、経済活動が集中している」とか「感染対策が効果を発揮している」というのは明らかにデータには無い情報です。
与えられたデータ+ChatGPTが持っている情報を加味した上で示唆を出していることがわかりますね。
そういう意味では、新型コロナウイルス新規感染者のデータも有名すぎたのかもしれません。
データ加工
ここからは一般的なデータ加工をしてみたいと思います。
カラム名の理解、カラムレベルのデータ抽出くらいなら問題なくできることがわかってますので、もう少し計算が必要なことをさせてみます。
簡単な統計量を計算さる
まずは雑に分析させてみます。扱うデータは新型コロナウイルス新規感染者のデータです。
質問内容:「このデータを分析したいです。よろしくお願いします。」

そうですよね。まずはデータ概要やカラム説明をしますよね。
ジャブとしては合格です。
続いては、基礎統計量を計算させます。
質問内容:「基礎統計量を計算して表にしてください。」
回答:
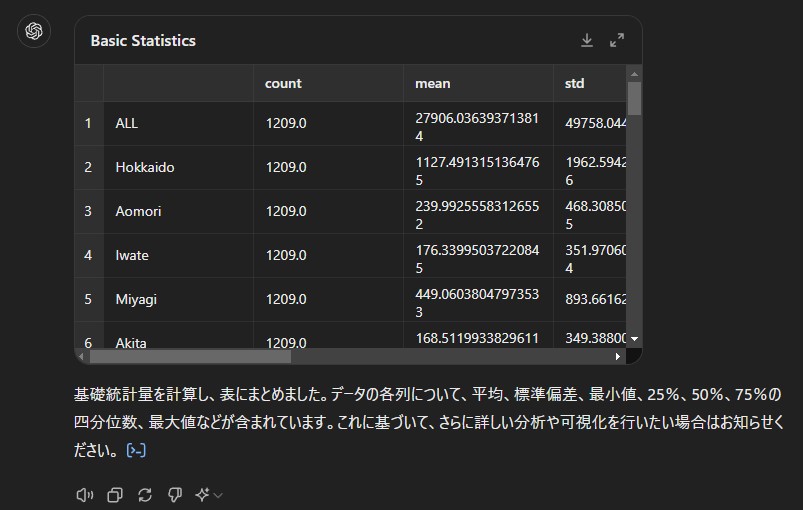
普通にPythonのdescribe()機能を使った結果が出てきました。すごいです。
あれ、ChatGPT 4oってPythonを動かすような計算リソースも使えるんでしたっけ?
特徴量エンジニアリングをしてみる
まずは与えられたデータに対してどのような特徴量エンジニアリングが考えられるか?聞いてみます。
質問内容:「感染者数予測をする上で、先ほどのデータに対して特徴量園エンジニアリングをしたいです。どのような加工をすると精度が上がりそうでしょうか?」
回答:

画像は途中で途切れてますが、かなりたくさんの特徴量エンジニアリングの方向性を示してくれました。
どうやら、一般的な内容であれば普通に分析ができてしまいますね。
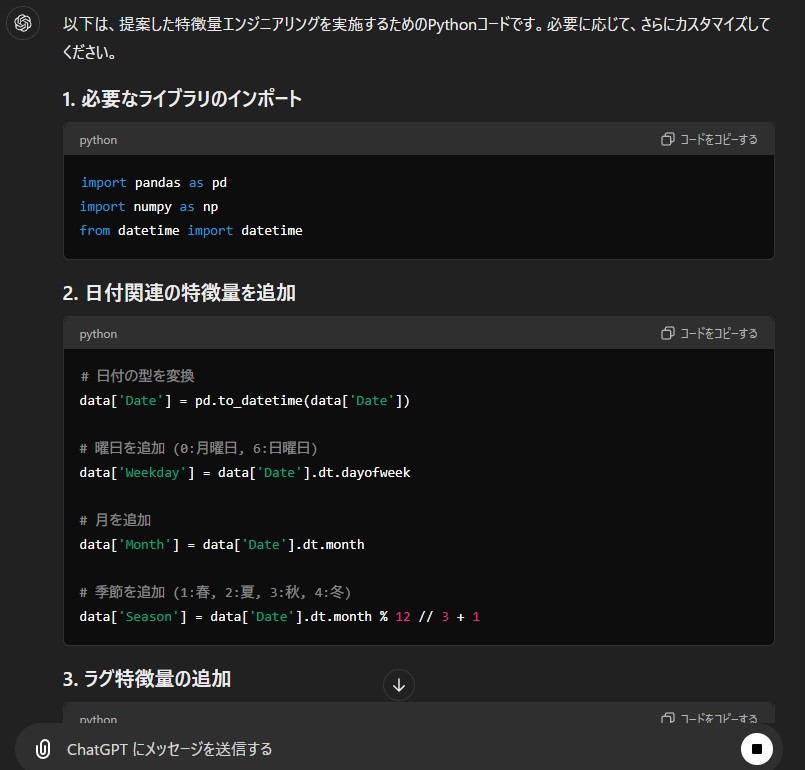
Pythonコードを出力させる
ちなみに、Pythonコードもしっかり示してくれます。
まとめ
- ChatGPTを使ったデータ分析はもう実用レベル。ゼロから分析することはなくなる。
- データ概要理解、可視化、集計、特徴量エンジニアリングは可能
- 一般的な知識と照らし合わせた考察もしてくれる
- Pythonコードの提示もしてくれる
- ChatGPTに計算能力が備わっているような挙動を見せてくれるが、実際に計算させているのか、生成なのか、調査が必要
- まぁデータ分析、データサイエンスで飯が食える時代は近いうち終わる(今はまだ大丈夫)
- ChatGPTに「逆に貴様は何を持ちえないのだ」と言いたい。


コメント