
みんな大好きツイッターですが、用意されているAPIを使うと簡単に全世界で発信されているツイート内容を取得することができます。
今回はPythonのTweepyを使ってツイートの取得を行っていきます。
1. 開発者用アカウントを申請
Twitter APIを使用するためにはすでに持っているツイッターアカウントを用いて申請が必要になります。
1)以下URLから申請開始
デベロッパーポータル:https://developer.twitter.com/en/docs/developer-portal/overview
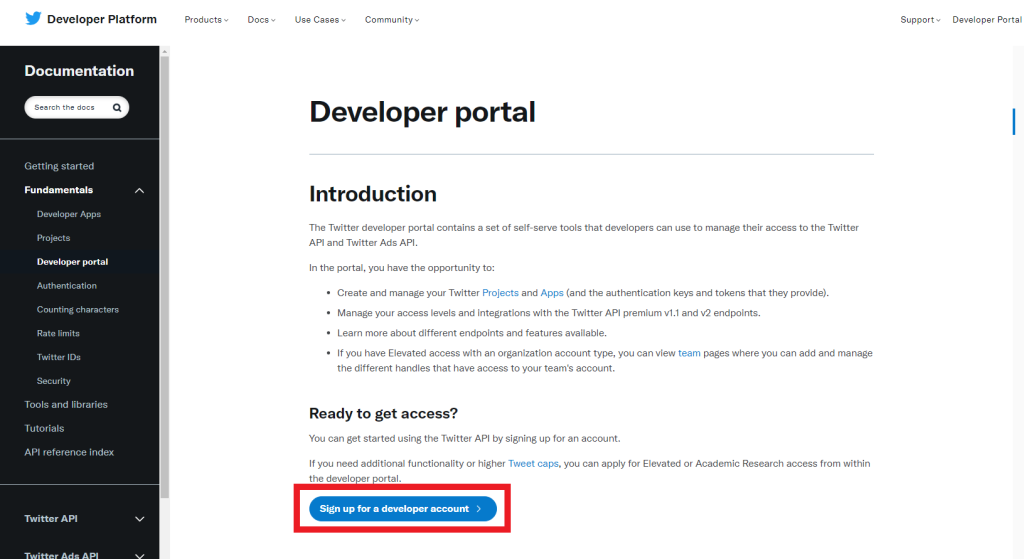
2) 必要項目を入れて、「Let’s do this」を押す
※Emailはご自身のツイッターアカウント上で登録しておく必要があります。(ヘルプ)
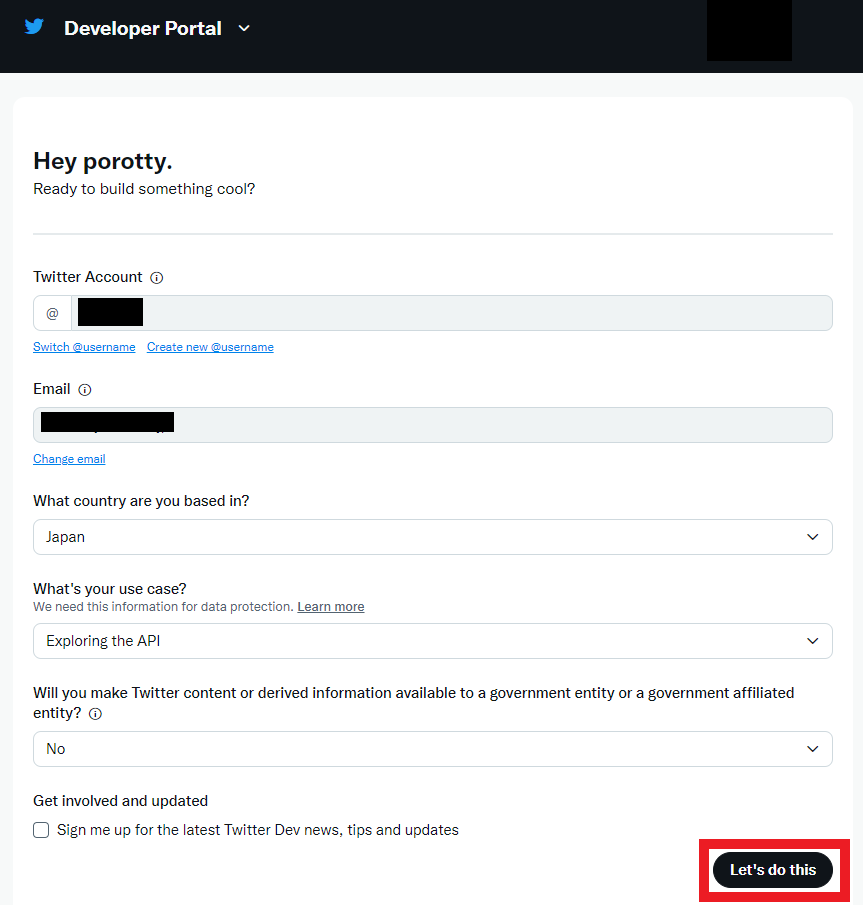
3) ポリシーに同意
※「Submit」を押したときツイッターのアカウントに電話番号を登録してないとエラーで弾かれてしまう
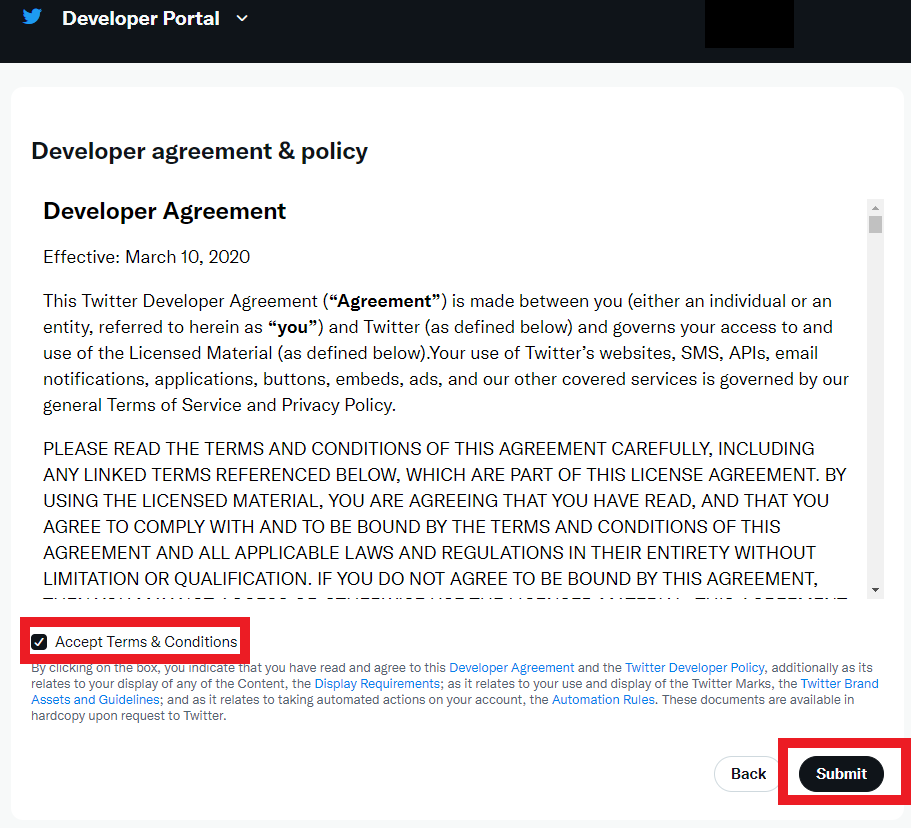
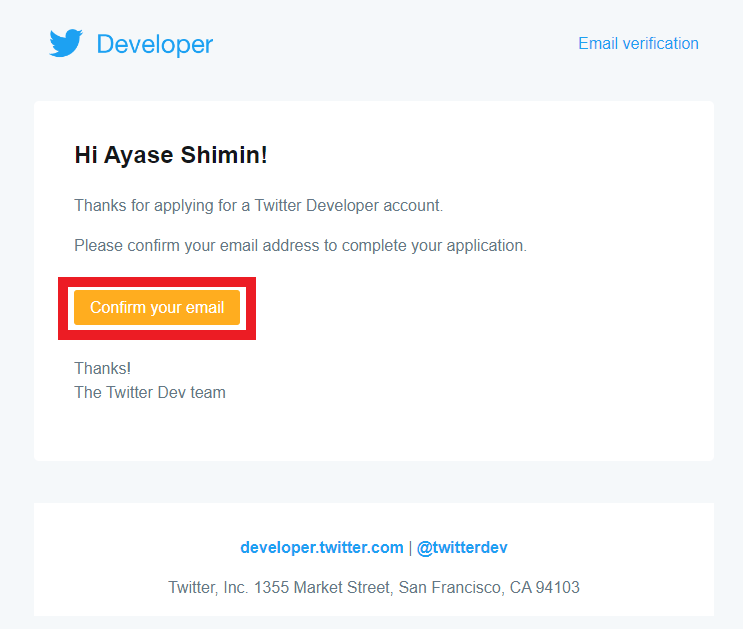
4) 確認メールが登録されているアドレスに届く
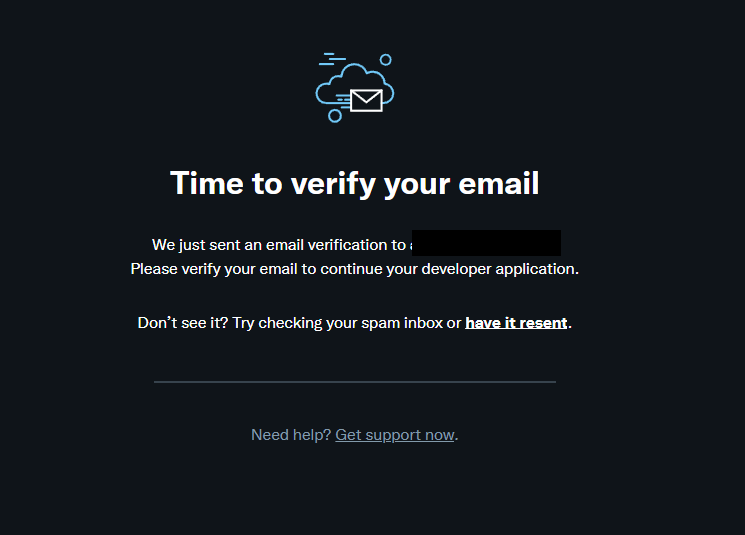
5) 届いたメールの「Confirm your email」を押して、申請完了!
2. APIキーとアクセストークンの取得
続いてAPIキーとアクセストークンの取得です。
APIキーとアクセストークンはPythonのTweepyを使ってツイートを取得する際に、認証情報として必要になります。
Tweepyの認証に必要となるキーは以下の4つ
- API key
- API key secret
- Access token
- Access token secret
それでは取得していきましょう。
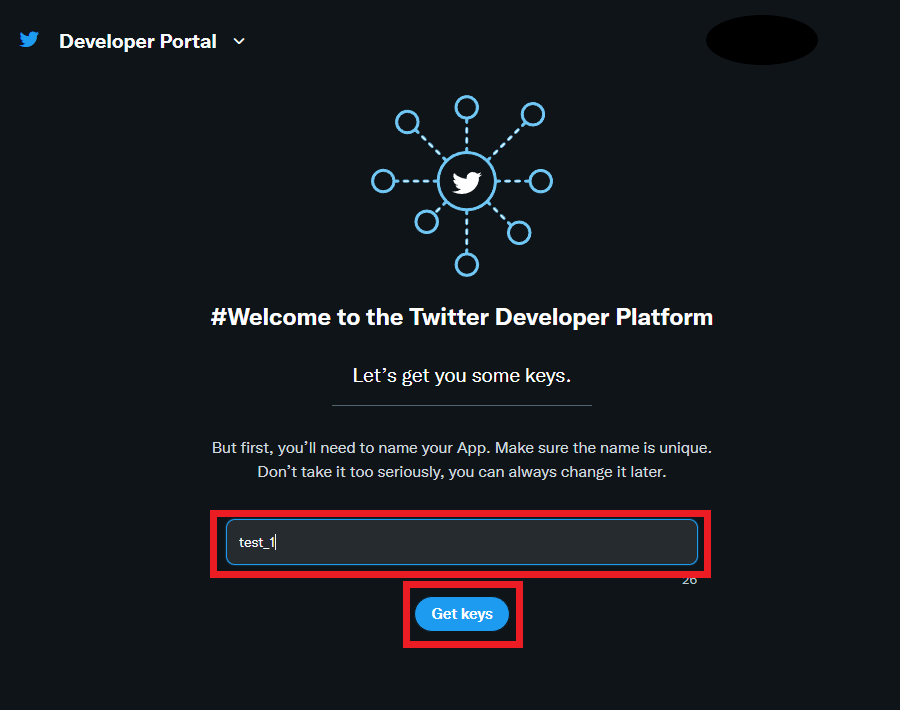
1) Appネームを適当に入力し、「Get keys」を押す
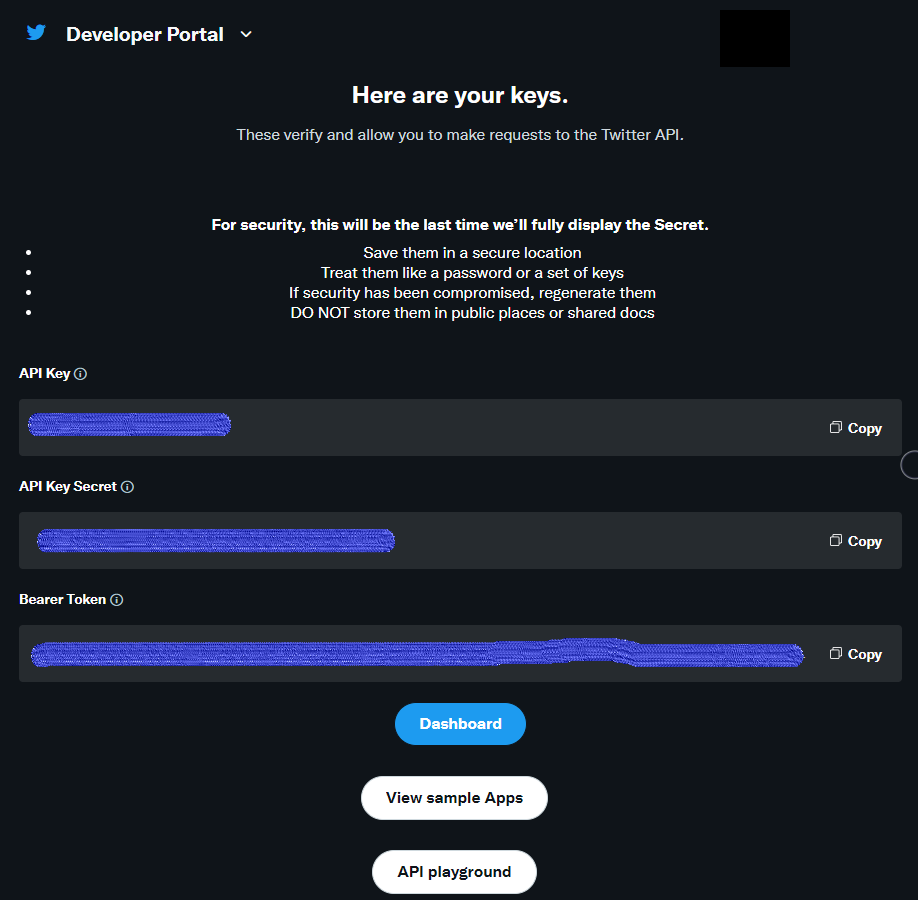
2) API keyとAPI key secretが表示される
※ ここではメモを取らなくてもOK
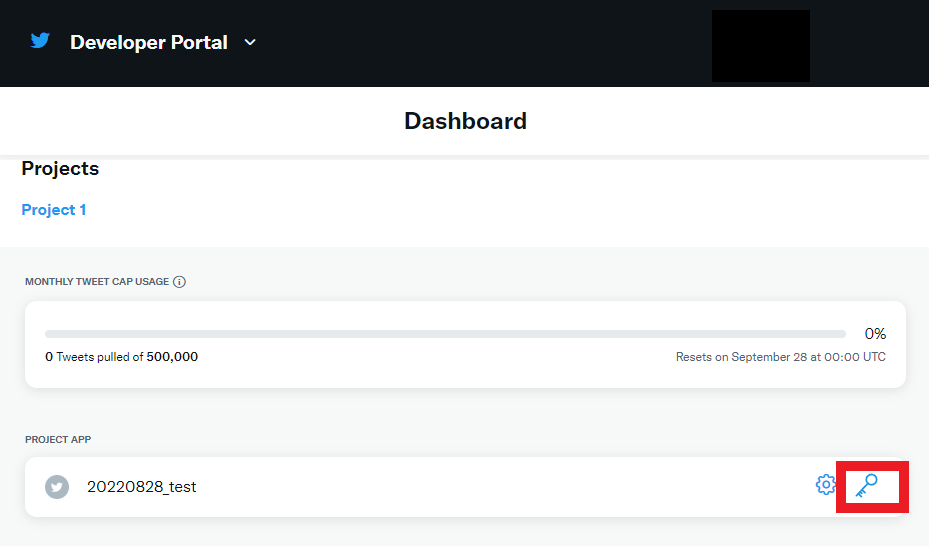
3) 「Dashboard」からさきほど作成したAPPのカギアイコンをクリック
4) 「Access Token and Secret」の「Generate」をクリック
5) 表示された”API key”, “API Key Secret”, “Access Token”, “Access Token Secret”をそれぞれコピー
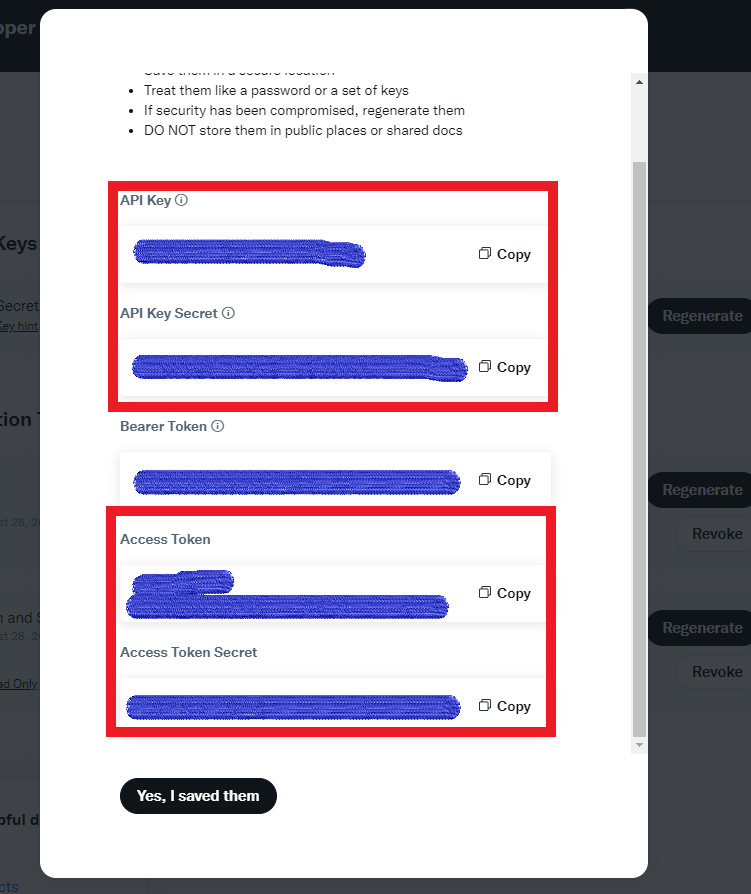
6) 取得完了!!
3. Tweepyを使ってツイートを取得
ここからはPythonのお出ましです。
PythonのツイッターAPIライブラリTweepyを使っていきます。
Tweepyを使うと、ツイッター上の基本的な操作はすべてPython上で行うことができます。
(ちなみに、フォロワーの削除はdestroy_friendshipととてもユニークな関数名です。)
まずはTweepyのpipインストールをしておきましょう。
pip install tweepy
続いて、先ほど入手したAPIキーとアクセストークンを使って認証を行います。
import tweepy
import pandas as pd
# API key
API_key = '*****'
# API key secret
API_key_secret ='*****'
# Access Token
AT ='*****'
# Access Token secret
ATS ='*****'
# API keyとAPI key secretをOAuthHandlerに渡してやる
auth = tweepy.OAuthHandler(API_key, API_key_secret)
# 次に、AT(Access Tokent)とATS(Access Token secret)をセット
auth.set_access_token(AT, ATS)
# 認証開始!
api = tweepy.API(auth)問題なく実行できましたか?続いて、ツイートを取得していきます!
4. ツイートを取得してDataFrame化
ツイートの取得方法は下記以外にもいくつかあります。
ここでは、キーワード検索でツイートを取得する方法を試します。
キーワード検索以外の取得方法はこちらを参照:https://docs.tweepy.org/en/stable/api.html#tweets
実際のPythonコードです。
# ツイート検索
tweets=tweepy.Cursor(api.search_tweets,
q='ひろゆき', # 検索ワードを指定
tweet_mode='extended', # 省略されたツイートを表示
result_type="recent", # recent:直近のツイート、popular:いいねが多いツイート、mixed:両方を加味
count=100, # 一度に取得するツイート数
).items()
# 取得結果から必要なデータのみ抽出
tw_data=[]
for tweet in tweets:
tw_data.append([
tweet.id, # ツイートID
tweet.created_at, # ツイート時刻
tweet.full_text, # ツイート本文
tweet.favorite_count, # いいね数
tweet.retweet_count, # リツイート数
tweet.user.id, # ユーザID
tweet.user.screen_name, # ユーザ名
])
# そしてDataFrame化へ(いいね数でソート)
labels=['ツイートID','ツイート時刻','ツイート本文','いいね数','リツイート数','ID','ユーザー名']
df=pd.DataFrame(tw_data,columns=labels).sort_values(by='いいね数',ascending=False)
実行結果
なんとかDataFrame化までいきました。
まとめ
Pythonのデータフレームの形まで落とし込むことができれば、ここからはアイデア次第でいかようにもできてしまいますね。
集計、可視化、データ分析をするもよし!
ワードクラウドを作成するもよし!
自然言語解析をするもよし!
何か面白そうなことができる予感がしませんか??


コメント