
最近流行りのAIに興味を持ち出して、それなりのデータを持っているお客様が、
「データこんだけあるんだ。これで何か良いモデルを作ってくれないか?」
と、自信満々に訪ねてくるわけです。
「…まるでわかっちゃいねぇな。そんな甘っちょろいデータで予測モデルを作るつもりかい?」
と、お客様に対して答えるのです。
このようなやり取りはビジネスにおいてよくあります。
実は、データは多いに越したことはないのですが、ちゃんと意味のあるデータでないと機械学習の効果は得られません。
では、”意味のあるデータ”とはなんでしょうか?
そのデータ、個性はあるか?

時系列データでなければ、データの1行1行は独立しています。
機械学習における良いモデルを作るためには、データを構成する1行の中にどれくらい多くの情報が含まれているか?ということが重要です。
例えば、以下のようなデータを使ってモデルを作成するとしましょう。
| No. | 名前 | 所属部署 | 担当地域 | 上司名 | 売上 |
| 1 | 佐藤 | 営業1課 | エリアA | 高橋 | 100万 |
| 2 | 田中 | 営業2課 | エリアB | 斎藤 | 80万 |
| 3 | 鈴木 | 営業2課 | エリアA | 渡辺 | 50万 |
| … | … | … | … | … | … |
このデータを使って売上を予測する機械学習モデルを作っても、間違いなく良いモデルは作れません。断言できます。
では、このデータの何が悪いのでしょうか?
(決してデータが悪いわけではなく、機械学習向きではないということです)
それは、このデータのほとんどが属性データであり情報量が少なすぎることが問題なのです。
つまり、ターゲットである売上を予測するのに必要な情報が少ないのです。
このようなデータではどんなにたくさん集めてきても精度の高い予測モデルを作成することはできません。
では逆に、個性のあるデータとはどういうものでしょうか?
例えば以下のようなデータです。
| No. | 保有スキル | 社歴 | 担当顧客数 | 担当地域 | メール数 | 顧客訪問数 | 売上 |
| 1 | 資格A | 10年 | 10 | エリアA | 10 | 7 | 100万 |
| 2 | 資格B | 8年 | 13 | エリアB | 14 | 8 | 80万 |
| 3 | 資格C | 2年 | 8 | エリアA | 3 | 8 | 50万 |
| … | … | … | … | … |
このデータであれば、予測をする上で必要となる情報が先ほどより多くなっています。
人間の判断基準からしても、
「顧客数が多ければ売上は多きいだろう」
とか
「営業活動を多くこなしてる方が実績を出してるだろう」
といったなんとなくの仮説を思い浮かべることができると思います。
機械学習でも同じです。
企業においてこういった(機械学習には)使えないデータを自信満々に溜めていることは往々にしてあります。
機械学習モデルを作成するときに我々は”データの質と量”を重点的にチェックします。
そのデータ、偏ってない?

データは時にして偏りが存在します。
そんな偏りのあるデータで機械学習モデルを作成すると、その偏りに大きく引っ張られた形のモデルとなってしまします。
また、データ点の少ない領域では予測結果の精度が落ちてしまうことにも注意が必要です。
実際には以下の図のように、データの分布がわかれていると機械学習的には
予測しにくい領域となります。
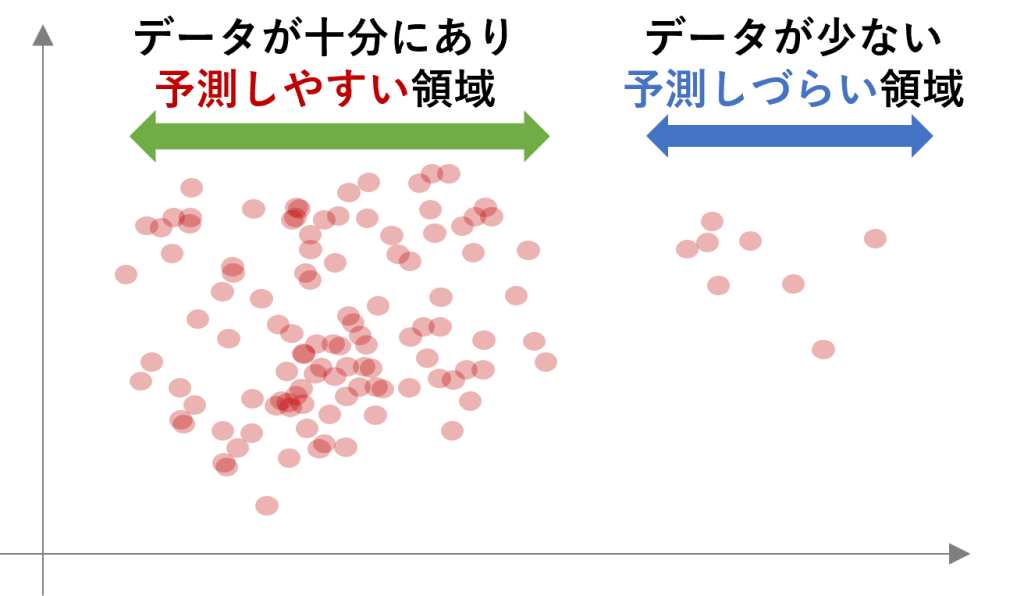
図 データの偏りの例
つまり、学習データの範囲内であれば精度よく予測することができますが、学習範囲外のデータに対して予測精度は悪くなってしまいます。
機械学習業界で言う外装問題ですね。
機械学習は人間と同様、過去の情報がない領域については予測させることが困難なのです。
まずはデータに偏りがないか、以下の点を押さえておきましょう。
- データ全体を可視化し(散布図やヒストグラムを見る)、偏りがないか見てみる!
⇒もし偏りがある場合はデータの背景知識からの判断が必要。データを分割するのも手。そのまま使うのも手 - 学習データと予測データの傾向が似ているか確認する
⇒2つの集団の分布が異なるかどうかをχ(カイ)2乗検定を使って統計的に学習データ、評価データを調べるのも吉
また、外装問題については使用するアルゴリズムによっても精度は異なります。
例えば、ツリー系のアルゴリズムではYes/Noの分岐を複数回繰り返すような処理を行うので、データ点少ない場所では荒い分岐となってしまい、外装領域のデータを予測しようとすると精度はすこぶる悪くなります。
一方で、線形アルゴリズムでは外装領域であっても線形の関係性があるので比較的精度が良い可能性があります。
従って、交差検定やホールドアウトの精度が良いからと言って精度の高いモデル1つだけで判断するのは少し危険です。
系統の異なる複数のモデルを選択し、評価してやることが重要となります。
データを取得する目的はそもそも機械学習のためではない
![]()
データを取得する目的はたくさんあります。
トレーサビリティの観点だったり、セキュリティ目的だったり、モニタリングのためかもしれません。
”毎日の日記”だって立派なデータになり得ます。
たいていの場合、機械学習を使うこと前提でデータが蓄積されているわけではないのが事実です。
なので、機械学習のために「量と質のあるデータを持ってこい!」というのは、もしかしたらデータサイエンティストのエゴかもしれません。
そもそもの使用目的が異なるデータを使って利益が出せるようなデータサイエンスができたら、むしろそれはめちゃくちゃラッキーなことだと思います。
もしくは、データ取得の設計段階でそこまで考えていた超優秀な人がいたのかもしれません。
データがないからといって諦めるにはまだ早いです。
まずは今手元にあるデータを使ってモデリングをして精度評価ができないか、データサイエンティストの方に相談してみましょう。
それでもし精度が全然でないようだったら、精度改善に繋がる仮説をたくさん出し合って、手に入りそうなデータから入手してまたモデリングを行う。
このサイクルを繰り返せば良いのです。

ということでこれから機械学習に手を出そうという方や、精度改善で悩んでいる方は一度自分のデータを見直してみてください。
以上!


コメント