
前回に引き続き、データ収集をやっていきます。
競馬予測チャレンジ目次!
-
データ取得編2(スピード指数取得) ⇦本記事はココ
-
実践編
競馬予測するためにはデータが必要になります。今回は競馬の予測でよく用いられるスピード指数を無料で収集していきます。
競馬に必要なデータはどこから入手するか?
競馬関連の情報が手に入るサイトはいくつかありますが、次の二つを使いました。
- netkeiba.com ⇦前回の記事で実施
- 競馬新聞&スピード指数(無料) ⇦今回の内容
1つ目のnetkeiba.comでは過去に行われたレース情報がタダで入手できます。
2つ目の競馬新聞&スピード指数(無料)では、netkeiba.comでは手に入らない(有料会員で閲覧可能)、スピード指数と呼ばれる情報を手に入れるために使います。
どうやってデータを抽出するか?
今回も大活躍!PythonのBeautiful Soupライブラリを使ってスクレイピングします。
ウェブページを開いてパソコンのF12を押すとウェブページを構成するスクリプトが表示されます。
ここから馬の名前や過去の結果等の必要な情報を取得していきます。
URLの構成
今回情報を取得する(スレイピングする)対象は競馬新聞&スピード指数(無料)という競馬情報サイトです。
それではさっそくこのサイトのURL構成を分析してみましょう。
ウェブサイトのデータベースにあるレース情報をなんでもいいので複数開いてみると次の6つの要素から構成されていることがわかります。
(例)http://jiro8.sakura.ne.jp/index.php?code=2005050901
5回 東京 9日目 第1レース
- URL冒頭の「http://jiro8.sakura.ne.jp/index.php?code=」(これは固定)
- レースの開催年の西暦(下2桁)
- 本記事では15年から20年を対象
- 開催場所(2桁)
- 10か所(札幌、函館、福島、新潟、東京、中山、中京、京都、阪神、小倉)
- 〇〇回(2桁)
- おそらく1~6回まで
- ○○日目(2桁)
- おそらく1~10日目まで
- 第〇レース(2桁)
- 第1レースから第12レース
ここまでわかれば、あとは機械的にfor文をひたすら回せばレース情報が記載されているウェブページを表示させることができそうです。
スクレイピングによる情報の抽出
用いる手法はPythonのBeautiful Soupライブラリを使います。
スクレイピングするときの注意点
まずはその前に、前項のパターンを全て足し合わせると6×10×6×10×12=約4万3千個のURLを処理することになります。
この数字、一見そこまで多くなさそうですが、
必ず、サーバに負荷を与えないように各リクエスト処理には毎回最低1秒の時間間隔を
設けて取得してください。※後のコードでも説明します。
つまり、全処理を実行すると単純計算で12時間かかることになります。
非常に長いです。
そこで、次のような時間短縮策も打ちます。(多少ましになる、程度ですが。。。)
- レースの途中で情報が欠けている場合、その日のその後のレース情報は取得しない
- 例)第4レースの情報がない場合、第5レース以降の情報はスキップする
- こまめに取得した情報をCSVファイルに保存する
- 何らかの原因でもし処理エラーになった場合に途中から再開できるようにするため
取得するデータ
netkeiba.comから取得できるデータ一覧はこちら!
| カラム名 | 例 | 目的 |
| 馬名 | ウインルーア | 結合用 |
| スピード指数 | 66.62 | こいつが目的 |
| 日付 | 2020年7月25日(土) 9:55 | 結合用 |
| レース情報 | 1回札幌1日 1R | 結合用 |
スクレイピング内容
さっそく、スクレイピングについて説明していきます。
わかりやすくするために、2020年東京で行われたとあるレースを見ていきます。
以下のスクレイピングのお作法に則って、表データ(table)を抽出します。
# まずは、スクレイピングしたいURLを指定
url='http://jiro8.sakura.ne.jp/index.php?code=2005050901'
# リクエストを送る際に必ず1秒間の時間を置きましょう
time.sleep(1)
# 冒頭で指定したURLからデータを取得します
html = requests.get(url)
# もし取得したデータが文字化けするようであれば入れてみてください
html.encoding = html.apparent_encoding
# BeautifulSoupを使って取得したデータを解析します
soup = BeautifulSoup(html.text, 'lxml')
# 取得したデータから表を取得する'table'タグのうちクラスが'c1'であるものを取得します。
table = soup.find('table',class_='c1')tableを見てるとtrタグがたくさん取得できます。このtrタグが表の1行分の情報が入っています。
例えば、
table.find_all('tr')[0]を見てみると”枠番”が取得できます。
こんな感じ。
<tr>
<td bgcolor="#FF6666" class="c21">8</td> # 枠番8
<td bgcolor="#FF6666" class="c31">8</td> # 枠番8
<td bgcolor="#FFCC66" class="c21">7</td> # 枠番7
<td bgcolor="#FFCC66" class="c31">7</td> # 枠番7
<td bgcolor="#99FFCC" class="c21">6</td> # 枠番6
<td bgcolor="#99FFCC" class="c31">6</td> # 枠番6
<td bgcolor="#FFFF66" class="c21">5</td> # 枠番5
<td bgcolor="#FFFF66" class="c31">5</td> # 枠番5
<td bgcolor="#66CCFF" class="c21">4</td> # 枠番4
<td bgcolor="#66CCFF" class="c31">4</td> # 枠番4
<td bgcolor="#FF3333" class="c21">3</td> # 枠番3
<td bgcolor="#FF3333" class="c31">3</td> # 枠番3
<td bgcolor="#808080" class="c21">2</td> # 枠番2
<td bgcolor="#808080" class="c31">2</td> # 枠番2
<td bgcolor="#eeeeee" class="c21">1</td> # 枠番1
<td bgcolor="#eeeeee" class="c31">1</td> # 枠番1
<td class="c54">枠番</td>
</tr>この以下の表の一番上の部分
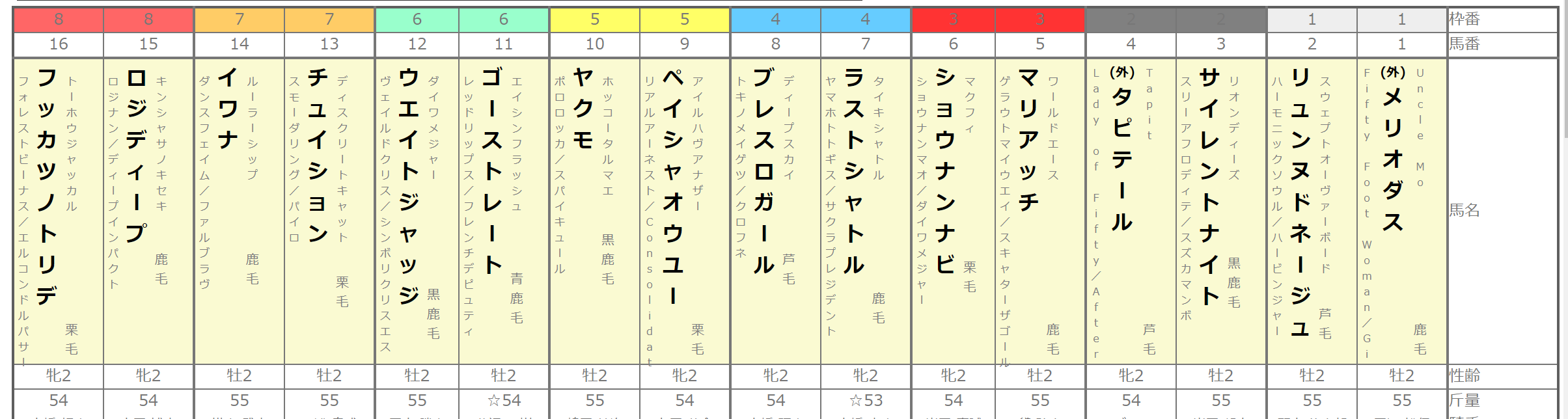
しかし、本当にほしいのは上から3行目の馬の名前ですよね。
馬名は3行目なので、次のコードを実行してみます。
table.find_all('tr')[2]すると、、、
</td><td class="c231" rowspan="2">
フ
<br>
ッ
<br>
カ
<br>
ツ
<br>
ノ
<br>
ト
<br>
リ
<br>
デ
<br>
</td>衝撃的事実。
表記を縦表記にするために馬名を一文字brタグで囲っていたんですね…これは少し骨が折れそうです。
馬名として認識するための処理を入れてやる必要がありそうです。
ちなみに、今回の目的となるスピード指数は表の67行目に出てきます。
table.find_all('tr')[67]注意点としては、スピード指数は毎回67行目にあるとは限らない点です。かなり面倒です。
今回の中身はこんな感じ。
<tr>
<td class="c27">35.98</td>
<td bgcolor="#F0F8FF" class="c37">28.56</td>
<td class="c27">19.61</td>
<td class="c37">35.46</td>
<td class="c27">15.77</td>
<td class="c37">16.24</td>
<td class="c27">18.55</td>
<td bgcolor="#F0F8FF" class="c37">57.36</td>
<td class="c27">37.72</td>
<td class="c37">38.38</td>
<td class="c27">54.74</td>
<td class="c37">20.48</td>
<td class="c27">59.18</td>
<td bgcolor="#F0F8FF" class="c37">67.86</td>
<td class="c27">58.42</td>
<td class="c37">34.93</td>
<td class="c53">スピード指数</td>
</tr>trタグの中にレースに参加している馬の数だけtdタグがあります。
tdタグに挟まれて入っている数値がスピード指数です。
スクレイピングコード例※実行するときは自己責任でお願いします。
さて、必要な情報は抽出できそうなことがわかりましたので実際のコード例を。
import requests from tqdm
import tqdm
import time from bs4
import BeautifulSoup
import pandas as pd
import re
flg=0
flg2=0
# URLの変更しない部分
base='http://jiro8.sakura.ne.jp/index.php?code='
check=[]
# 2015年から2020年の6年分
for year in tqdm(range(15, 21)):
umamei=[] # 馬名を格納するリスト
speed=[] # スピード指数を格納するリスト
date=[] # 日付を格納するリスト
# 競馬の場所10か所分
for basyo in range(1,11):
# 回目
for times in range(1,7):
# 日目
for day in range(1,10):
# データが取れない時のループ短縮用
if flg2 == 1:
flg2=0
print('日スキップ')
break
# 1から12レースをループ
for rd in range(1,13):
url=base+str(year).zfill(2)+str(basyo).zfill(2)+str(times).zfill(2)+str(day).zfill(2)+str(rd).zfill(2)
temp1=[] # 馬名の仮格納用リスト
temp2=[] # スピード指数の仮格納用リスト
temp3=[] # 日付仮格納用リスト
for _ in range(3):
try:
# リクエストを複数回実行するときは1秒の間隔をあける
time.sleep(1)
html = requests.get(url)
except:
print('error?')
pass else:
break
html.encoding = html.apparent_encoding
soup = BeautifulSoup(html.text, 'lxml')
table = soup.find('table',class_='c1')
# tableが空白等の場合はループをスキップ、かつ、 # checkは重複があったときはループをスキップ
if (table == []) | (table == None) | (len(set(check)) != len(check)):
print('break',url)
flg2=1
check=[] break
else:
try:
for td in table.find_all('tr')[2].find_all('td',class_='c231'):
a=''
n=0
# tdタグ内のbrタグを除去し、馬名を取得。
# 1文字ずつこの時伸ばし棒の「|」を「ー」に変換
for i in td.contents:
n=n+1
if n%2==1:
if i == 'l':
i='ー'
a=a+str(i)
else:
continue
# 馬名を連結し、temp1に追加
temp1.append(a)
# 日付を抽出し、temp2に追加
temp2.append(re.split("\u3000",soup.find('nobr').contents[1].strip()))
# trタグの数(表の行数)だけfor文を回す。
for tr in table.find_all('tr'): if tr.find_all('td',class_='c53')!=[]:
# スピード指数の位置がズレると面倒なのでスピード指数の文字とマッチした
# trの情報を抽出
if tr.find_all('td',class_='c53')[0].string=='スピード指数':
for td in tr.contents[:-1]:
# スピード指数をtemp3に追加
temp3.append(td.string)
flg=0
# 機械的にfor文を回すと、たまに規則に合わないURLにヒットする場合があり、
# なぜか余計なデータを収集してしまい、行が重複してしまうことが発覚。 # なので重複回避のためにそのレースに出場した馬名を全て連結し、
# checkに追加し、↑の方で重複があった場合にスキップするように処理
check.append('-'.join(temp1[-12:]))
except:
flg=1
pass
# 馬名のtemp1とスピード指数のtemp3はリスト長が一致するはずなので
# もし異なる場合はカウントしない。じゃないと結合する際に行がズレて大変なことに
if (flg == 0) & (len(temp1) == len(temp3)):
umamei=umamei+temp1 # 馬名をumameiリストに追加
date=date+temp2 # 日付をdateリストに追加
speed=speed+temp3 # スピード指数も同様にリストに追加
print(len(umamei),len(speed),'OK',url)
else:
print('NG',url)
flg=0
# 年が変わるタイミングでumamei、date、speedをDataFrame化して結合し、csvファイルに保存
pd.concat([pd.DataFrame(umamei),pd.DataFrame(speed),pd.DataFrame(date)],axis=1).to_csv('speed_info_'+str(year)+'.csv',encoding='utf_8_sig')ちなみにこのコードは処理が完了するまで20時間くらいかかります。
for文がたくさん処理されたり、リストに追加したりする処理でどうしても時間を食ってしまい、理想通りにはいきません。
もっと効率の良いやり方があればぜひ教えていただきたいです。
次は…
さて、ようやくデータが揃いました!
次はデータの結合、そして特徴量生成です!
お楽しみに!


コメント