
AIや機械学習という言葉がもてはやされてから数年が経ちます。
ですが、いまだに「AIはなんでもできる夢の道具」と思っている経営者や上層部が多く、結果頓挫してしまうケースが多いように思います。
せっかくデータを利活用しようと息巻いてプロジェクトを発足しても残念な結果となってしまう失敗例を今回はお伝えしたいと思います。
失敗理由①目的が曖昧で予測結果をどう使うかが見えていない
よくある失敗例としては、AIを導入するという目的のみが先行してしまい、何を予測する?予測結果をどう使うの?というところが曖昧になってしまいっているケースです。
プロジェクトは複数人、またはチームをまたいで複数チームで取り組むことも少なくありません。
目的が曖昧なままプロジェクトが走ってしまうと失速し、必ず失敗に終わります。
【ダメな例】 ”AIを導入して売上アップをめざそう!”
よく目にしそうな内容ですが、単に「売上アップを目指そう」というのは絶対にNGです。
なぜならばAIで予測をした結果起こせるアクションが何も明確になっていないからです。
”何を予測して、予測した結果同アクションを起こすのか”をちゃんと意識して目標設定をする必要があります。
そんなに難しいことではありません。以下を意識してみてください。
- 現場で困っていることはなんなのか?
→課題設定 - 困っていることを解決するには何がわかれば(予測できれば)良いのか?
→目的変数、アクションの設定 - 困っていることが解決するとどのような良いこと(利益やコスト効果)があるのか?
→効果の試算
まずは課題を明らかにしましょう。そしてその課題を解決するためにはどうやってAIを使えばいいのかしっかりと考えてからプロジェクトを立ち上げましょう。
失敗理由②必要なデータがわかっていない、集められない
予測対象が定まったら次のステップはデータ集め。
そもそもこのデータ集めですが、機械学習を用いて何を解決したいのかが明確になっていないと、どのようなデータを集めてくればよいのか曖昧になってしまします。
データ収集は非常にたくさんの挫折ポイントがあります。私自身が体験した点をいくつか紹介します
- データを保持している部隊が別で、データをもらうのにもスタンプラリーが発生
- データの中身を見てみるとほとんどが空データ、またはユニーク数1のデータ
- そもそも(デジタル)データなんてものはなかった
上記3つは本当によく出会うシチュエーションだと思います。
データ分析プロジェクトをやりたいのにデータは違うチームが担当していたり、個人情報に近いデータだと、データベースから取り出すのに書類を作成して上長のスタンプラリーが必要だったり、データを扱えるようになるまで長い道のりがあったりします。
しかしながらこれらは仕方ないことでもあります。そもそもデータベースにアクセスするということはデータ流出、改ざん(意図せず)のリスクがあったりしますし、セキュリティ面を考えると他社、他チームにデータを渡すのは非常に怖いと思うのが実情です。
システム面においてもデータを取り出して分析するためにデータを溜めたり、設計されているわけではないですからね。
苦労して手に入れたデータにも注意が必要です。大体の場合、データ分析を行う部隊とデータを管理する部隊は異なりますので、当然データの構成やデータの意味については確認が必要です。
でないと、時間をかけて分析した結果がまるで意味のないモノになってしまうことも少なくありません。
失敗理由③組織体制が整っていない
先にデータの話をしてしまいましたが、プロジェクトを立ち上げると同時に考えないといけない問題の一つが組織体制です。
プロジェクトを推進するにあたっては他部門との連携および上長、さらにその上の経営者への成果の報告は必須となります。
プレジェクトをサポートしてくれるスポンサーにうまいこと報告をしないと、プロジェクトは上手くいかない可能性が高いです。
AIはなんでも叶えてくれる道具ではないというところ含めて、皆さんでプロジェクト推進を意識していくことが必要となるでしょう。
以下の体制図の例ではかならず必要となる人たちを上げています。
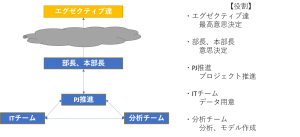
エグゼクティブ達
最高意思決定者です。AIプロジェクトは時に数億円以上の利益に繋がる可能性があります。
こんな大きな利益のあるプロジェクトを推進するためにはコストもある程度必要となります。
プロジェクトの目的、得られる利益、コストは必ず気にするところなので明確にする必要があります。
エグゼクティブ達を味方に付けることができれば、トップダウンで動いてくれない部署を動かすこともできるでしょう。
部長、本部長
プロジェクトの結果を受けて、社内テーマや金額規模によってはこの辺りのランクの方々で意思決定することが可能になるかと思います。
PJ推進
プロジェクトをまとめる人たちです。上手くITチームおよび分析チームと連携を取って、上の人たちに報告する役割です。データサイエンティストやプロジェクトマネージャーが該当します。
ITチーム
システムの運用をしていて、データの取り出し等を行います。インフラエンジニアやデータベースエンジニアが該当します。
分析チーム
データの加工やデータ分析、機械学習モデリングを行います。データアナリストやデータサイエンティストが該当します。
失敗理由まとめ”プロジェクトを成功させるには”
まとめです。以下3点をしっかり意識しながらプロジェクトを立ち上げる必要があります。
・AIプロジェクトの目的をはっきりとさせる
・必要なデータが揃うか確認を行う
・他チーム、上長みんなを巻き込んで体制を作る
どれか一つでもできていないと、そのAIプロジェクトは失敗する可能性が高いと言えます。
以上です。


コメント