
生成AIの技術的な部分についても触れていきます。
ひとまず、皆さんご存じのChatGPTに代表されるLLM(大規模言語モデル)を取り上げます。
LLM(大規模言語モデル)とは
LLMとは、膨大な量のテキストデータと最先端のディープラーニング技術を用いて訓練された、AIの一種です。
その名の通り、従来の言語モデルと比べて圧倒的に大規模にすることで、人間のような流暢な会話や、創造的な文章生成、高度な翻訳、複雑な質問への回答など、様々な自然言語処理タスクにおいて高い能力を発揮することができます。
きっかけは、Open AI社が2020年に大規模言語モデルに関する論文(Scaling Laws for Neural Language Models)が始まりのようです。
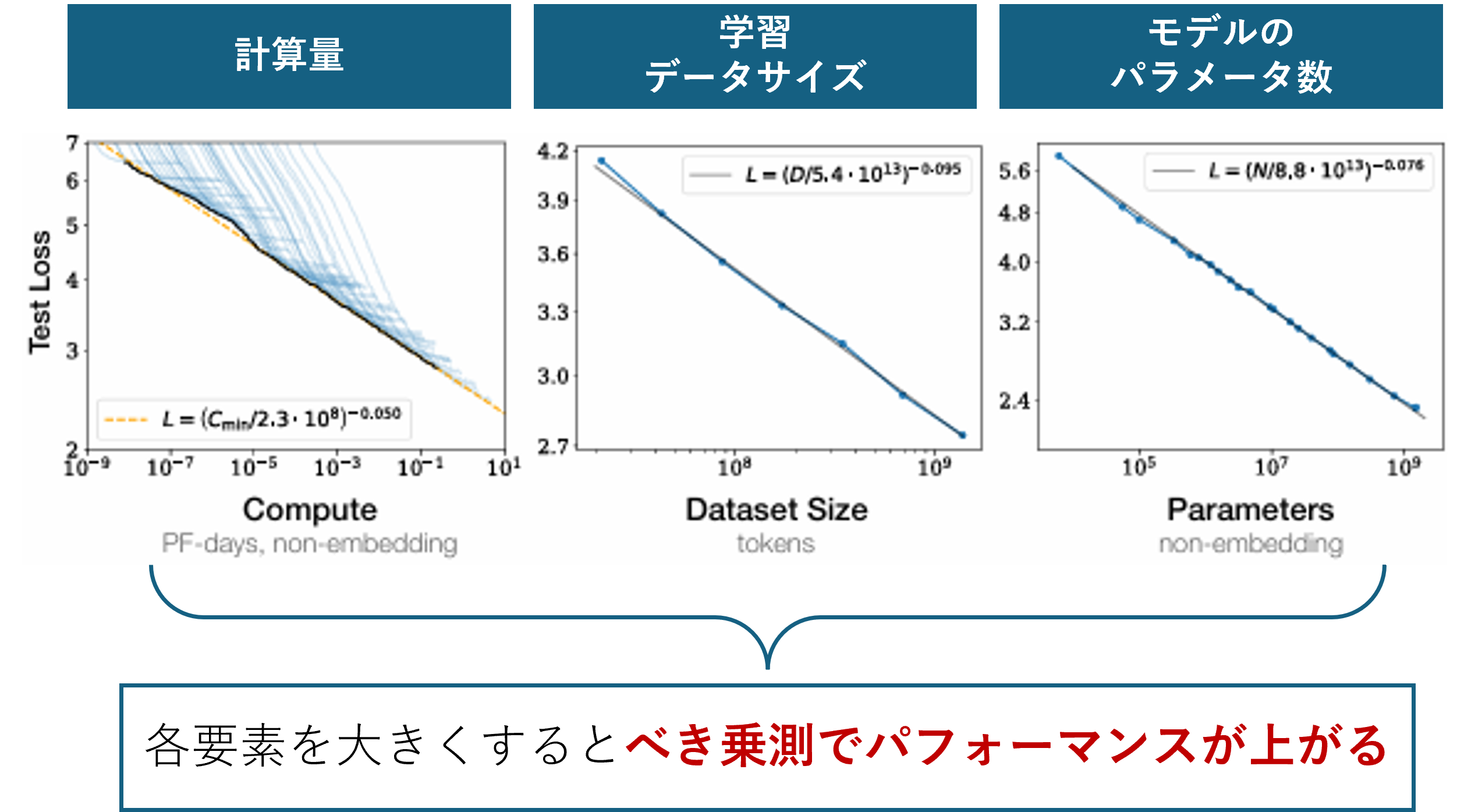
この論文の中で、言語モデルの性能はスケールと呼ばれる以下3つの要素に強く依存していると言われています。
- モデル学習の計算量
- 学習に使うデータ量
- モデルのパラメータ数
つまり、難しいことは抜きにして、言語モデルを大規模にすればするほどパフォーマンスの高いモデルが作られるということが実証されたということで、大規模言語モデル(LLM)が流行ることになりました。
Open AI社のChatGPTやGoogleのBERTなどはこの大規模言語モデルを元に、自然言語を介して会話ができるように応用したAIです。
厳密な区分けは異なるようですが、これらのサービスをまとめてLLMと呼ぶ人も結構多い印象です。
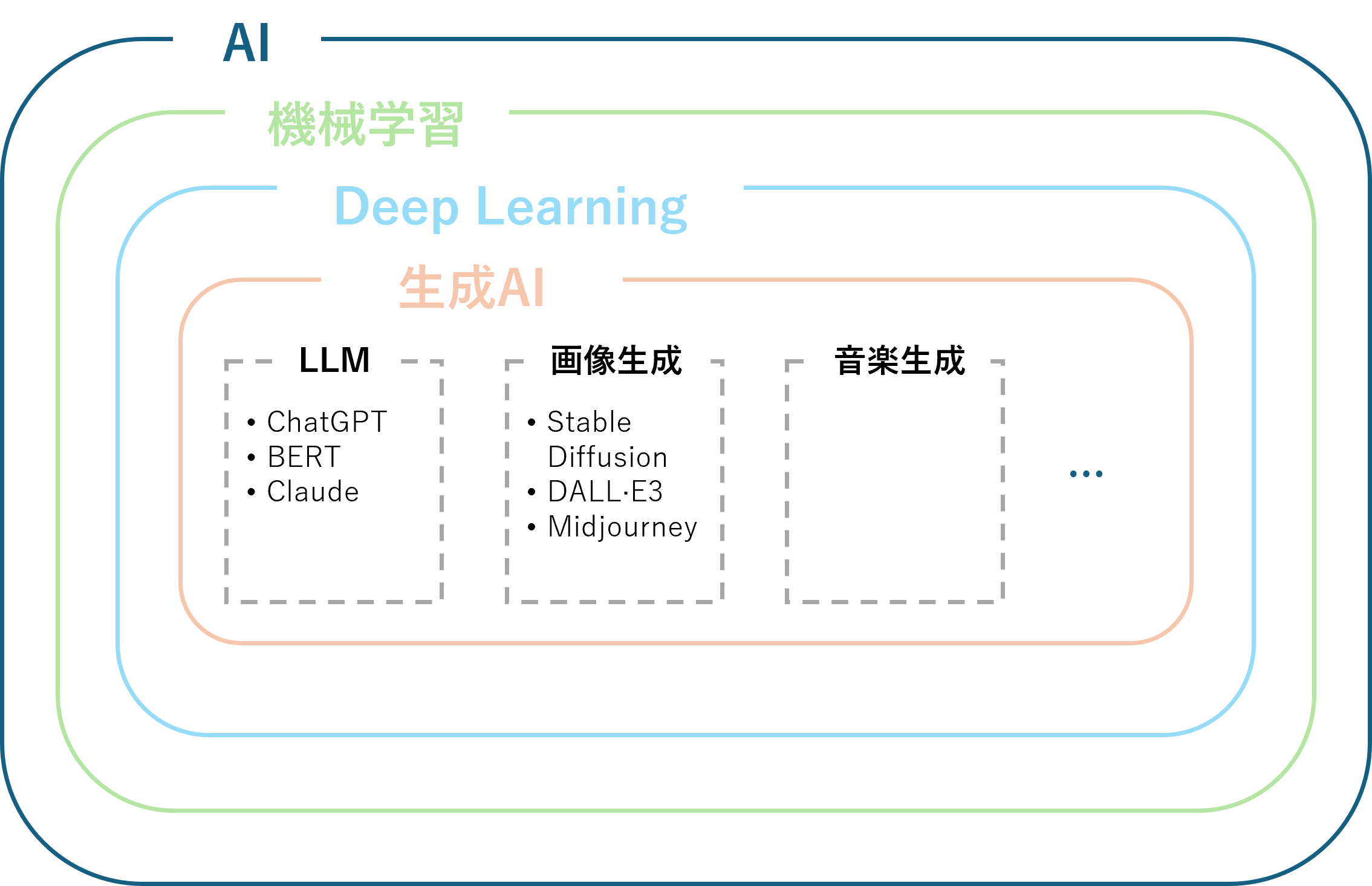
Deep Learningの一種:生成AIの位置づけ
世間でのLLMの使われ方
2024年5月にOpen AIからGPT-4oがリリースされ、世間をより騒がせていましたが、
実際にLLMを使う場合は、ChatGPTのように各社から提供されるサービスとして使うのが一般的です。
ただし、そのままLMMを使うのでは不都合な点がいくつがあります。
代表的な課題を3つ上げます
- ネット上に出回っていない社内文書や専門的な情報については答えてくれない
- 社内で使うためには業務と関係ないことや、不適切な質問に答えさせたくない
- セキュリティ面が不安
これらを解決するために、LLMと合わせて複数の技術を掛け合わせて対応していくのが基本です。
RAG(検索拡張生成)による未学習情報の対応
LLMはネット上や書籍など一般的な情報から学習しています。
そのため、学習していない情報については正しく答えることができません。
そこで用いるのがRAG(検索拡張生成)と呼ばれる技術で、社内規約などのLLMが持ち合わせていないデータをDBに格納し、質問の際にはこのDBからの検索結果と合わせてLLMに投げます。
LLMは検索結果と質問内容に合う形で回答します。(以下図参照)
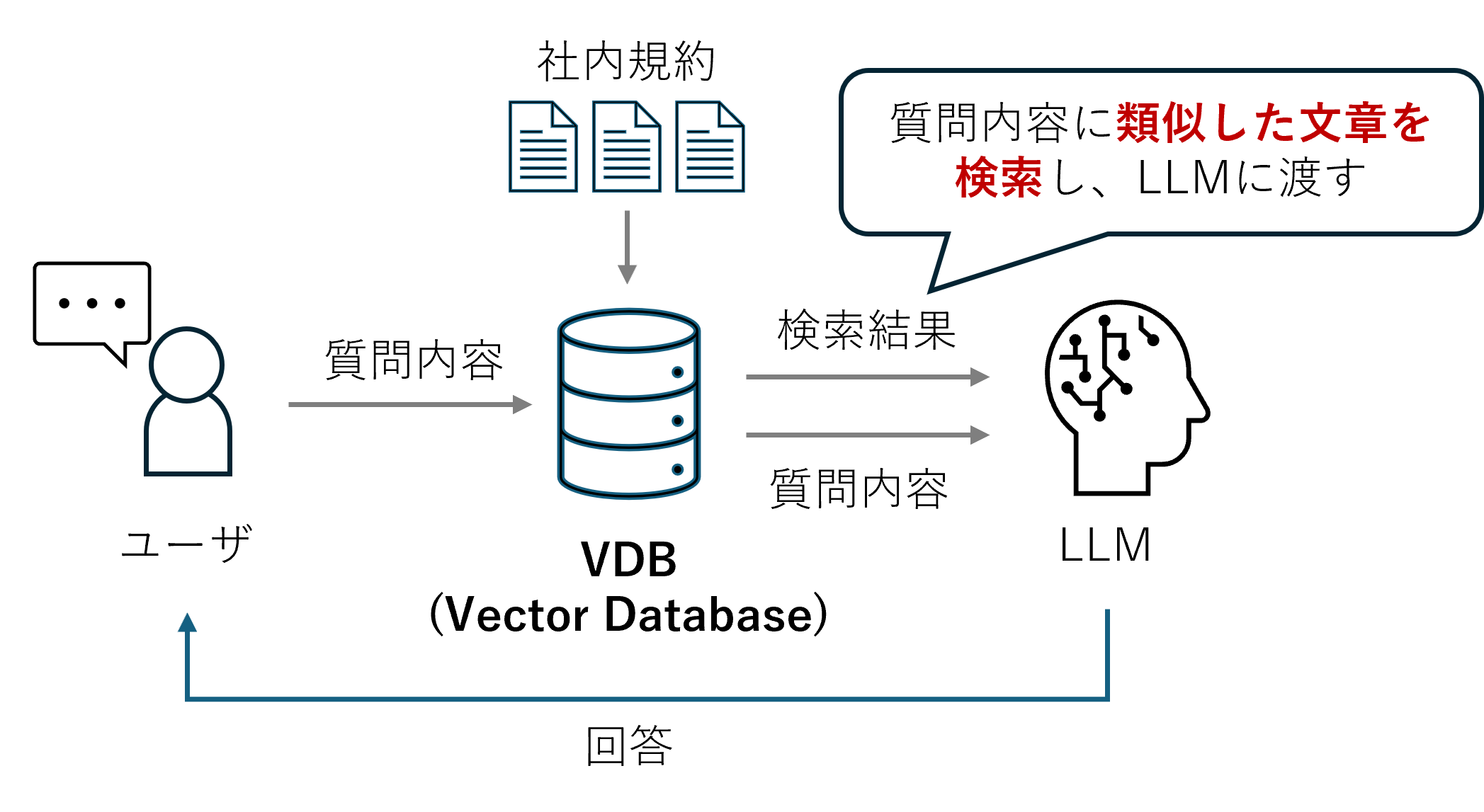 RAGを利用したLLMのイメージ図
RAGを利用したLLMのイメージ図
このように、LLMが持っていない知識を横づけする形で補うことができるのです。
RAGのメリット・デメリットも簡単にまとめておきます。
| メリット | デメリット |
| 情報の更新が楽ちん | RAG構築のためのデータ整備が必要 |
| 低コスト | システムが複雑になる |
| RAGの設計次第で柔軟なシステムが可能 | 回答の速度が遅い |
LLMを追加学習させる
いわゆるディープラーニング界で有名なファインチューニングのことです。
LLMは大量の学習データとバケモノクラスのGPUを用いて学習がされています。
この学習済みのモデルに対して新しい情報を追加的に学習させるのが追加学習です。
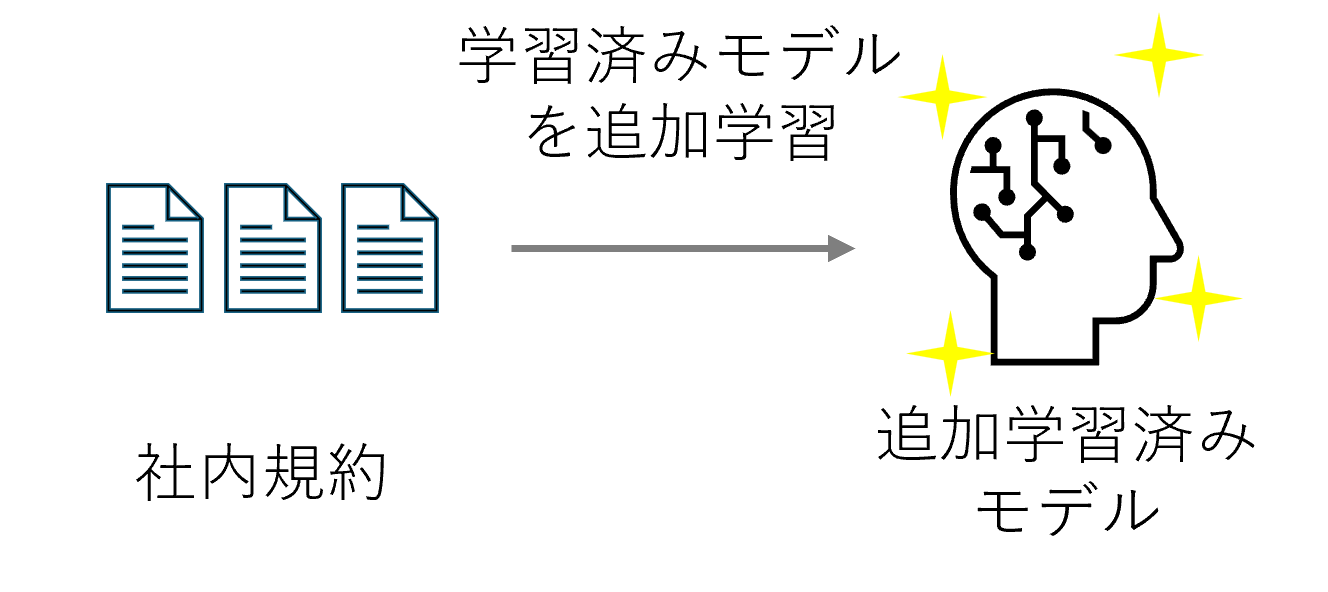
しかし、この追加学習が選択肢に入るケースはなかなかないかもしれません。
メリット・デメリットをまとめてみます。
| メリット | デメリット |
| RAGに比べて応答速度が速い | 情報更新の度に追加学習が必要 |
| RAGに比べて構成がシンプル | 学習内容の精度は向上するが、他が下がる可能性がある |
| 追加学習にはそれなりの計算資源が必要 | |
一言で言うと、追加学習は扱いが難しいのです。
そもそもLLMは一般的に使えるようにチューニングにチューニングを重ねて学習された、言わばバランスの良いモデルです。
追加学習によってこのバランスを崩すことになるので、一部の精度は上がったとしても当然全体的な精度は不安になってしまう、という理解が近いでしょう。
NTTのLLMであるtsuzumiは果敢にも独自の追加学習手法が使われているとのことで要注目です(参照)
プロンプトエンジニアリング
人間が他の人からアドバイスをもらうときに、ちゃんと背景やストーリーもセットにして話した方が、的確なアドバイスがもらえますよね。
それと同じことがLLMでも言えます。
プロンプトエンジニアリングは、LLMに入力するプロンプトに背景知識や役割などを付与して入力することでLLMの回答のパフォーマンスを向上させる基本的な技術です。
具体的には次のような情報を加えて、LLMに入力します。
- 命令:LLMに実行させたいタスク、指示
- 背景:質問の背景や想定している役割、外部情報
- 入力:質問内容
- 出力形式:出力させたい形式、タイプ
プロンプトエンジニアリングは、もちろんLLMに質問するときに一緒に打ち込んで使うやり方もOKですが、用途を絞った使い方を行う場合はアプリやサービスの裏側で予め仕込んでおくことも多いと思います。
ただし、プロンプトエンジニアリング場合はどうしても文字数が増えてしまうのでトークン数(一度に入力する文字数)を無駄に消費してしまうことに注意が必要です。
まとめ
今回の記事ではLLMをより便利にする技術として3つを紹介しました。
- RAG(検索拡張生成)
- 追加学習(ファインチューニング)
- プロンプトエンジニアリング
生成AIを取り入れたけど意外と上手くいかない…と悩んでいる声をよく聞きます。
現在ではRAGがよく選択されていますが、実際は実現したサービスやシステムそして運用方法を考慮して柔軟に選択していくのが得策でしょう。


コメント